
今年以来,ChatGPT引领了全球人工智能的新一轮创新浪潮。以中国为例,据《2023—2024年中国人工智能计算力发展评估报告》显示,截至2023年10月,中国累计发布两百余个大模型(包括基础和行业类),已进入“百模大战”的新时代,在彰显我国人工智能领域创新实力和发展潜力的同时,对如何选择和走出具有中国特色的大模型发展之路也提出了挑战。

心急吃不了热豆腐,“全能”基础大模型才是基石
提及国内的“百模大战”,可谓是百花齐放,但从属性上分,基本为基础和行业模型两大类,出于尽早进入市场,尝试尽快实现商业变现的需求,国内大模型的发展有向行业模型倾斜的趋势,甚至出现了针对基础模型不要“重复造轮子”的论调。事实真的如此吗?
2021年8月,李飞飞和100多位学者联名发表一份200多页的研究报告《On the Opportunities and Risk of Foundation Models》中提出了基础模型(Foundation Model)(《On the Opportunities and Risk of Foundation Models》,国际上称为预训练模型,即通过在大规模宽泛的数据上进行训练后能适应一系列下游任务的模型。
相较于小模型或者所谓行业模型(针对特定场景需求、使用行业数据训练出来的模型),基础模型优势主要体现在以下几个方面。
首先是涌现能力,它指的是模型规模超过某个参数阈值后,AI效果将不再是随机概率事件。在通用领域,参数量越大,智能通常涌现的可能性就越大,AI准确率也会更高。在专用垂直领域,基础模型裁剪优化后更容易获得精确的效果;
其次是适用场景广泛。人工智能大模型通过在海量、多类型的场景数据中学习,能够总结不同场景、不同业务下的通用能力,摆脱了小模型场景碎片化、难以复用的局限性,为大规模落地人工智能应用提供可能;
最后是研发效率提高。传统小模型研发普遍为手工作坊式,高度依赖人工标注数据和人工调优调参,研发成本高、周期长、效率低。大模型则将研发模式升级为大规模工厂式,采用自监督学习方法,减少对特定数据的依赖,显著降低人力成本、提升研发效率。
此外,基础大模型还具有同质化特性,即基础模型的能力是智能的中心与核心,它的任何一点改进会迅速覆盖整个社区,反之隐患在于大模型的缺陷也会被所有下游模型所继承。而这又从反面证明了基础大模型作为小模型基础的重要性。
以当下流行的GPT-4为例,其实它就是一个能力强大的基础大模型,没有行业属性,通用智能是其最核心的部分,对于所谓的小模型或者面向行业场景的行业模型来说,基础大模型结合行业数据和行业知识库,就可以在行业中实现更高效的落地,这里最典型的例子就是微软推出的基于GPT-4平台的新Bing和Copilot应用。而其背后揭示的则是通过发展基础大模型,构建技能模型,进而落地行业模型,符合大模型自身技术发展规律的必由之路。
所谓心急吃不了热豆腐。当我们在基础大模型这块基石尚不牢固,盲目追求所谓落地的技能和行业模型的速度,很可能是重复造轮子,同时,鉴于目前以GPT为代表的基础模型迭代很快,性能提升明显,届时,我们的技能和行业模型还面临技术过时(行业和技能模型还不如基础模型)的风险而事倍功半。
夯实基础模型,面临高质量数据与算法创新挑战
既然我们理解了基础模型基石的技术逻辑和作用,夯实基础模型自然是重中之重。但对于国内来说,夯实基础大模型却面临不小的新挑战。
首先是缺少多样化、高质量的训练数据。
以GPT为例,在数据多样化方面,GPT-1使用的训练语料以书籍为主、如BookCorpus等;GPT-2则使用了如Reddit links等新闻类数据,文本规范质量高,同时又包含了部分人们日常交流的社交数据;进入GPT-3,模型的数据规模呈数十倍增长,Reddit links、Common Crawl、WebText2、Wikipedia等数据集的加入,大大提高了数据的多样性;GPT-4阶段更引入了GitHub代码、对话数据以及一些数学应用题,甚至增加了多模态数据。
在数据质量方面,以GPT-3模型为例,其训练需要的语料75%是英文,3%是中文,还有一些西班牙文、法文、德文等语料集,这些学习语料可通过公开数据(如维基百科、百度百科、微博、知乎等)、开源数据集、网页爬取(训练GPT-3爬取了31亿个网页,约3000亿词)、私有数据集(如OpenAI的WebText数据集,收集了Reddit平台上的800万篇高赞文章,约150亿词)等方式获取。这些语料中,英文语料公开数据更多、质量更高。
需要说明的是,尽管上述已是高质量的数据,但其来源于维基百科、书籍及学术期刊等的高质量数据也仅占其数据集的17.8%,但其在模型训练中的权重却占到了40%,数据质量精益求精和重要性可见一斑。

对此,有业内分析认为,当高质量数据量到达一定临界值的时候,将会无限拉近不同算法带来的准确率差距,某种程度上会决定模型训练的质量,不仅让训练变得更加高效,同时可以大幅削减训练成本。
相比之下,中文开源高质量数据少,特别是构建基础大模型的百科类、问答类、图书文献、学术论文、报纸杂志等高质量中文内容。同时,国内专业数据服务还处于起步阶段,可用于人工智能模型训练的经过加工、清洗、标注的高质量数据集还相对匮乏。
由此可见,缺少高质量、多样化的训练数据已成为国内基础模型训练的核心痛点之一,也是最大的挑战。
除了高质量的数据之外,纵观当前国内的大模型,基本都是基于Transformer架构,技术原理业内都相当清楚,但为什么ChatGPT就是比其他大模型表现得更好?由于GPT-3之后,OpenAI的所有模型没有再开源,GPT-4的运行机制是什么,国内企业仍无从得知,但在业内看来,其核心理应是算法的创新和优化。
这里以Transformer架构为例,如上述,目前学术界大部分的工作都是围绕如何提升Transformer的效率展开,硬件结构也都是围绕如何优化Transformer的方式而设计,虽然其为业内带来了创新突破,但仍然存在某些局限性。例如,对于长序列的处理和对序列中的顺序信息的处理算法,会增加算力消耗和成本,而这为改进注意力机制、剪枝和量化等这些当前未曾突破的瓶颈与值得创新的发展方向提出了挑战,即想从架构上对Transformer进行创新,需要的是勇气与探索能力。
对症下药,开源、开放的源2.0带来了什么?
俗话说:挑战与机遇并存,而将挑战化为机遇的方法就是对症下药。而在这方面,浪潮信息日前发布的源2.0基础大模型颇值得我们拿来探究。
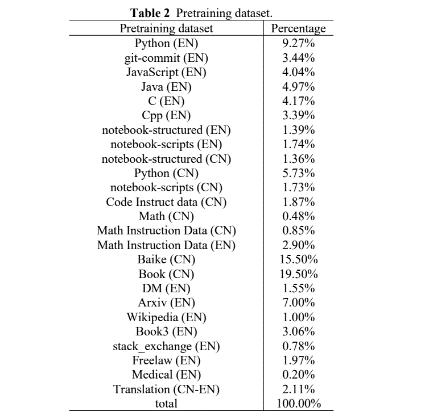
例如在应对我们前述的缺少多样化、高质量的训练数据挑战方面,源2.0的数据来源包含三个部分,分别是业界的开源数据、从互联网上清洗的数据和模型合成的数据。浪潮信息的模型团队不仅对2018年至2023年的互联网数据进行了清洗,从总量12PB左右的数据中仅获取到约10GB的中文数学数据,而为进一步弥补高质量数据集的匮乏,还基于大模型构建了一批多样性的高质量数据,为此,浪潮信息提出了基于主题词或Q&A问答对自动生成编程题目和答案的数据集生成流程,大幅提高了数据集问题的多样性。同时,辅以基于单元测试的数据清洗方法,让高质量数据集的获取更加高效,进一步提高训练效率。
具体来说,在构建高质量的数学和代码数据时,团队会随机选取一批种子数据,然后对其进行扩充,让大模型生成一批合适的问题,再把它们送到模型里,从而产生合适的答案。并将其补充到训练数据集当中。
不仅如此,即便是基于大模型构建的高质量数据,浪潮信息还会通过额外构建的数据清洗流程,力求将更高质量的社群、代码数据应用到模型的预训练过程中。可见源2.0对于数据的质量也是精益求精。而未来,浪潮信息的模型团队还会利用自己的模型生成更高质量的数据,形成数据循环,持续迭代并提升大模型的能力。
同样在应对算法挑战方面,源2.0也进行了重大创新,在我们上述的Transformer结构中完全替换了自注意力层,创新型地提出新型Attention结构,即局部注意力过滤增强机制LFA(Localized Filtering-based Attention),通过先强化相邻词之间的关联性,然后再计算全局关联性的方法,模型能够更好地处理自然语言的语序排列问题,对于中文语境的关联语义理解更准确、更人性,提升了模型的自然语言表达能力,进而提升了模型精度。
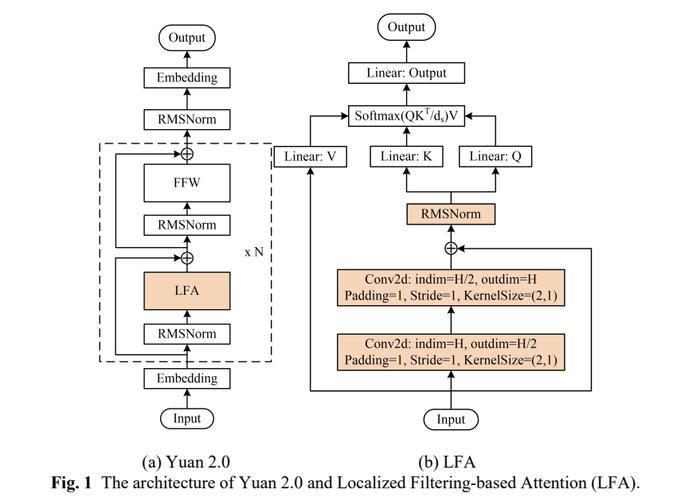
而消融实验的结果显示,相比传统注意力结构,LFA模型精度提高了3.53%;在最终的模型训练上,基于LFA算法的源2.0-102B模型,训练288B token的train loss为1.18,相比之下,源1.0 245B模型训练180B token的train loss为1.64。也就是说,从源1.0到源2.0,train loss降低了28%。
除上述之外,在算力上,源2.0采用了非均匀流水并行的方法,综合运用流水线并行+优化器参数并行+数据并行的策略,让模型在流水并行各阶段的显存占用量分布更均衡,避免出现显存瓶颈导致的训练效率降低的问题,该方法显著降低了大模型对芯片间P2P带宽的需求,为硬件差异较大训练环境提供了一种高性能的训练方法。
值一提的是,从当前大模型算力建设、模型开发和应用落地的实际需求出发,浪潮信息还开发出了全栈全流程的智算软件栈OGAI,以提供完善的工程化、自动化工具软件堆栈,帮助更多企业顺利跨越大模型研发应用门槛,充分释放大模型创新生产力。
所谓众人拾柴火焰高,这很好地诠释了开源、开放的理念。
具体基础大模型,不可否认的事实是,当前中国做大模型的公司与OpenAI仍存在较大差距,而开源能够释放整个社区的智慧,一起进行生态和能力的建设,这也是我们除了上述数据和算法的创新外,尽快追赶国外领先公司基础大模型的可行路径。
以浪潮信息近期公布的源大模型共训计划为例,其针对开发者自己的应用或场景需求,通过自研数据平台生成训练数据并对源大模型进行增强训练,训练后的模型依然在社区开源。开发者只需要提出需求,说清楚具体的应用场景、对大模型的能力需求以及1~2条示例,由源团队来进行数据准备、模型训练并开源。
由此可见,这种共享底层数据、算法和代码的共训计划,有利于打破大模型孤岛,促进模型之间协作和更新迭代,并推动AI开发变得更加灵活和高效。同时,开源开放有利于推进“技术+行业”的闭环,以更丰富的高质量行业数据反哺模型,克服数据分布偏移可能造成的基础大模型性能下降,打造更强的技术产品,加速商业化进程。
写在最后:综上,我们认为,“百模大战”,基础大模型为基,构建技能模型,进而落地行业模型,理应成为国内大模型现在和未来发展的共识,更是具有中国特色的大模型发展之路,而开源、开放的源2.0基础大模型的探索与实践只是开始!


