
使用 C++ 中的 final 关键字,到底能否提升性能?不少开发者认为可以,却没能给出数据依据。为此,本文作者进行了一次测试,亲自验证这个说法的真实性。
原文链接:https://16bpp.net/blog/post/the-performance-impact-of-cpp-final-keyword/
译者 | 郑丽媛
出品 | 程序人生(ID:coder_life)
如果你选择用 C++ 写代码,一定是有理由的,而这个理由很可能就是性能。
在很多有关 C++ 的文章中,我们经常会看到各种“性能提示和技巧”或“这样做效率更高”的建议。有时这些建议会给你一个合理的详细解释,但更多时候,你会发现没有任何实际数据支持这些说法。
最近我发现了一个奇怪的东西,那就是 final 关键字。说起来有些惭愧,我之前没怎么了解过这个关键词。许多博客文章都说,使用 final 可以提升性能,而且是免费的,只需进行微小改动。
但是,读完这些文章后,你会发现一个有趣的事实:没有人给出任何相关数据,基本上就纯靠一个“相信我吧,兄弟”。
从我的经验来看,除非有数据支持,否则任何性能提升的说法就全是空谈,甚至就算有了数据也得能够复现才行——因此,作为一名有着高性能 C++ 项目的优秀工程师,我真的很想验证这个说法。
有一个我认为非常适合测试 final 关键字的绝佳项目:PSRayTracing(https://github.com/define-private-public/PSRayTracing)。
简单介绍一下这个项目:这是一个用 C++ 实现的光线追踪器,源自 Peter Shirley 所写的光线跟踪系列书籍。它主要用于学术目的,但也结合了我编写 C++ 时的专业经验。项目目标是向读者展示如何(重新)编写 C++,使其性能更强、更简洁、结构更合理,因此在 Shirley 博士原始代码的基础上进行了补充和改进。PSRayTracing 有一个重要特性,能通过 CMake 切换代码的更改,还可以提供其他选项,如随机种子、多核渲染。


这是如何做到的?
利用构建系统,我在 CMakeLists.txt 中添加了一个额外选项:
option(WITH_FINAL "Use the `final` specifier on derived classes (faster?)" OFF)
# ...
if (WITH_FINAL)
message(STATUS "Using `final` spicifer (faster?)")
target_compile_definitions(PSRayTracing_StaticLibrary PUBLIC USE_FINAL)
else()
message(STATUS "Turned off use of `final` (slower?)")
endif()
然后在 C++ 中,我们可以使用预处理器来创建一个 FINAL 宏:
#ifdef USE_FINAL
#define FINAL final
#else
#define FINAL
#endif
而且,它可以轻松地添加到任何你感兴趣的类中:
$ rg FINAL
RandomGenerator.hpp
185:class RandomGenerator FINAL : public _GeneralizedRandomGenerator
{
Materials/Lambertian.hpp
8:class Lambertian FINAL : public IMaterial {
...
Materials/SurfaceNormal.hpp
7:class SurfaceNormal FINAL : public IMaterial {
...
PDFs/HittablePDF.hpp
7:class HittablePDF FINAL : public IPDF {
...
Objects/Sphere.hpp
19:class Sphere FINAL : public IHittable {
这样,我们就可以在代码库中随时开始和停止对 final 关键字的使用了。
当然,你可能会说这个方法太过繁琐,我也这么觉得。但不得不说,这很适合用来做对照试验:将 final 关键字应用到代码中,并根据实验需要使用或关闭它。
几乎每个接口都有 final 关键字。在架构中,我们有 IHittable、IMaterial、ITexture 等。在 Peter Shirley 光线跟踪系列的第二本书中,最后一个场景有很多超过 10K 个虚拟对象:

另外,有些场景的数量并不多(可能只有 10 个):


最初的担忧
对于 PSRT 来说,在测试可能提高性能的东西时,我首先使用的是默认场景 book2::final。启用 final 后,控制台报告如下:
$ ./PSRayTracing -n 100 -j 2
Scene: book2::final_scene
...
Render took 58.587 seconds
可随后又恢复了更改:
$ ./PSRayTracing -n 100 -j 2
Scene: book2::final_scene
...
Render took 57.53 seconds
我有点困惑,用了 final 反而更慢了?又跑了几次后,我发现性能下降得非常小,那些博客文章一定是在忽悠我……
不过在完全放弃之前,我想最好还是把验证测试脚本拿出来看看。在之前的版本中,这个脚本主要用于对 PSRayTracing 进行模糊测试,版本库中已经包含了一套小型的知名测试用例。
这套脚本最初运行大约需要 20 分钟,此时情况开始变得有趣:脚本报告称,使用 final 时速度稍快,运行时间为 11 分 29 秒;不使用 final 则为 11 分 44 秒。
看似只相差了 2% 的时长,实际上却很重要——我决定,要进一步调查。

大型测试
由于对以上结果不满意,我创建了一个“大型测试套件”,主要提高了一些测试参数以加强测试强度。在我的开发机器上,它需要运行 8 个小时。以下是调整后的详情:
● 场景测试次数:10 → 30
● 图像尺寸:[320x240, 400x400, 852x480] → [720x1280, 720x720, 1280x720]
● 光线深度:[10, 25, 50] → [20, 35, 50]
● 每像素采样次数:[5, 10, 25] → [25, 50, 75]
我认为这样更全面:现在有些测试用例只需 10 秒就能完成,有些则需要 10 分钟才能完成;小型测试套件在 20 多分钟内完成了约 350 个测试用例,而这个套件在 8 多小时内完成了 1150 多个测试用例。
考虑到 C++ 程序的性能与编译器(和系统)密切相关,因此为了更加彻底,我们在三台机器、三种操作系统和三种不同的编译器上都进行了测试;一次使用了 final,一次没使用。经过计算,这些计算机累计运行了 125 多小时。
具体情况请参见下表,另外配置如下:
● AMD Ryzen 9:
Linux:GCC & Clang
Windows:GCC & MSVC
● Apple M1 Mac:GCC & Clang
● Intel i7:Linux GCC
例如,一种配置是“AMD Ryzen 9,使用 Ubuntu Linux 和 GCC”,另一种是“Apple M1 Mac,使用 macOS 和 Clang”。注意,并非所有编译器的版本都相同,有些很难获得。另外在我发文的时候,Clang 还发布了一个新版本。下面是测试结果的总体摘要:

通过对比测试,我们可以看到一些有趣的结论,同时也告诉了我们一件事:从整体上看,使用 final 不能保证总是提速,甚至某些情况下速度还会更慢。
虽然在这个测试中对编译器进行比较可能也很有趣,但认为这样做并不公平:仅把“使用 final”和“不使用 final”进行比较才是公平的。如果想要比较编译器(以及不同系统),需要更全面的测试系统。
尽管如此,我们还是观察到了一些有趣的结果:
x86_64 上的 Clang 运行速度较慢。
Windows 性能较差,微软自己的编译器也很落后。
苹果公司的芯片则是绝对的强者。
但每个场景都不同,包含的标记为 final 的对象数量也不尽相同。按百分比来看,有多少测试用例在使用 final 后更快或更慢都很有趣。将这些数据列表,我们可以得到以下结果:
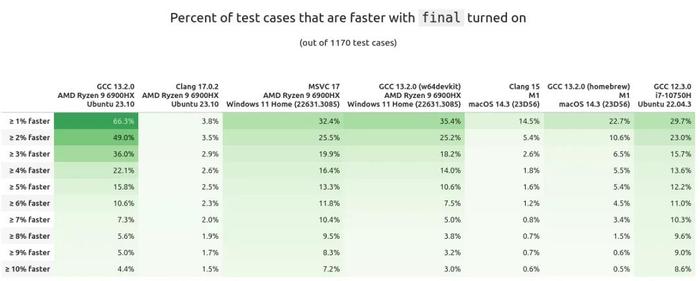
对于某些 C++ 应用程序来说,那 1% 的性能提升非常令人期待(例如,高频交易)。如果我们 50% 以上的测试用例都能达到这一点,那我们似乎应该考虑使用 final。但另一方面,我们还需要看看相反的情况:例如速度慢了多少?又有多少测试用例变慢了?

在 x86_64 Linux 上的 Clang 就绝对是一个典型:超过 90% 的测试用例在使用 final 后至少慢了 5%!!还记得我说过,对于某些应用程序来说,1% 的速度提升是件天大的好事吗?所以相对的,就算只慢了 1% 也绝不能容忍。此外,使用 MSVC 的 Windows 也表现不佳。
如上所述,这与场景有很大关系。有些场景只有少量的虚拟对象,有些则有一大堆。下面平均来看,使用 final 后一个场景的速度快了/慢了多少:

我对 Pandas 不是很了解,在创建一个多级索引表格(从数组中创建)并使其具有良好的样式和格式方面遇到了一些问题。因此,我在每一列名称的末尾都附加了一个配置编号。以下是每个数字的含义:
0 - GCC 13.2.0 AMD Ryzen 9 6900HX Ubuntu 23.10
1 - Clang 17.0.2 AMD Ryzen 9 6900HX Ubuntu 23.10
2 - MSVC 17 AMD Ryzen 9 6900HX Windows 11 Home (22631.3085)
3 - GCC 13.2.0 (w64devkit) AMD Ryzen 9 6900HX Windows 11 Home (22631.3085)
4 - Clang 15 M1 macOS 14.3 (23D56)
5 - GCC 13.2.0 (homebrew) M1 macOS 14.3 (23D56)
6 - GCC 12.3.0 i7-10750H Ubuntu 22.04.3
这就是让人眼前一亮的地方:在某些配置和特定场景下,性能可能会提升 10%!例如,在 AMD 和 Linux 上使用 GCC 的 book1::final_scene。但其他场景(在相同的配置下)仅有 0.5% 的提升,比如 fun::three_spheres。
但是,只是将编译器切换到 Clang(仍在 AMD 和 Linux 上运行)后,这两个场景的性能就分别下降了 5% 和 17%!MSVC(在 AMD 上)的情况有点复杂,有些场景在使用 final 时性能更高,有些场景则受到了很大影响。
苹果的 M1 有点意思,提速和降速幅度看起来都非常小,但 GCC 在两个场景上有显著优势。
另外,使用 final 后性能的提升或降低,几乎与虚拟对象数量是多是少没有关系。

我比较关注 Clang 的情况
PSRayTracing 也可在 Android 和 iOS 上运行。在这两个平台上,可能只有一小部分应用程序为了性能是用 C++ 编写的,而 Clang 正是用于这两个平台的编译器。
不幸的是,我没有像在桌面系统上那样的性能测试框架,但我可以做一个简单的“使用相同参数渲染场景,一个使用 final,一个不使用 final”的测试,因为应用程序会报告进程耗时。
根据上面的数据,我的假设是,这两个平台在使用 final 后性能会变差,但具体变差多少不清楚。以下是测试结果:
iPhone 12:我认为没有区别;无论使用 final 与否,渲染相同的场景都需要大约 2 分钟 36 秒。
Pixel 6 Pro:使用 final 后速度变慢了。渲染时间分别为 49 秒和 46 秒,3 秒的差异可能看起来不是很大,这相当于 6% 的减速,意义相当重大。
我不知道这是 Clang 的问题还是 LLVM 的问题。如果是后者,这可能对其他 LLVM 语言(如 Rust 和 Swift)也有影响。

未来的计划(以及我希望自己做的事情)
总的来说,我对这次测试发现的东西非常满意。如果我能重做一些事情(或得到一笔钱来做这个项目),我希望能做到以下几点:
让每个场景都能报告一些元数据。例如,对象数量、材质等。
对 Jupyter+Pandas 有更好的了解。虽然我是一位 C++ 开发者,不是数据科学家,但我希望能了解如何更好地转换测量结果,使其看起来更美观。
找到一种在 Android 和 iOS 上运行自动化测试的方法。目前这两个平台都不容易测试,这是一个很明显的问题。
run_verfication_tests.py 更像是一个应用程序(而不是一个小脚本)。
PNG 开始变得有些庞大,有一次我磁盘空间都不足了。无损 WebP 作为渲染输出可能更好。
比较更多的英特尔芯片,并使用更多的编译器。

结论
如果你只是匆匆翻到结尾,以下是总结:
使用 GCC 可能会得到一些好处。
对苹果芯片的影响不大。
不要在 Clang 和 MSVC 上使用 final。
这完全取决于你的配置/平台,请自主测试并衡量是否值得。
最后,就我个人而言,我应该不会用 C++ 的 final 关键字来提升性能,本文的测试结果说明了这种方式并不稳定。


