哇,一个模型中有 128 位专家。这比其他模型的专家数量都多得多。
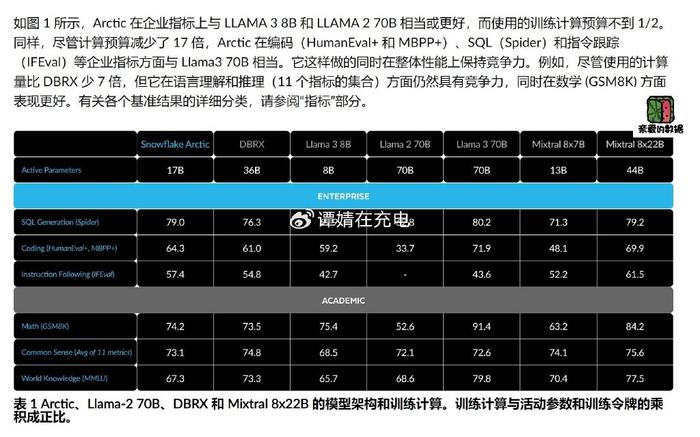
美国Snowflake公司(2024年4月24日)推出了Snowflake Arctic(雪花厂北极产品),这是一个4800亿参数的开源大型语言模型,这家基于云的数据仓库公司颇为自豪。
Snowflake 首席执行官Sridhar Ramaswamy出来讲了两句客套话,没啥干货。
不过,最终Snowflake还是拿出了开源模型。
以后,Snowflake、Databricks、META 和 Mistral 的开源模型会经常放在一起比较。
不过,只有少数模型专门针对企业任务。这就是Snowflake Arctic(雪花厂北极产品)的用武之地。
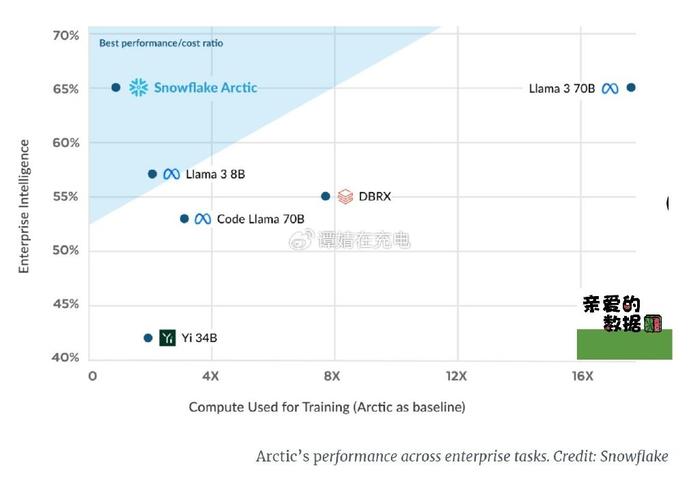
Snowflake Arctic有其特色:“针对复杂的企业工作负载(例如 SQL 生成、代码生成和指令跟踪)进行了优化。”Arctic 没有面向消费者的聊天机器人版本,只在github上有个demo。
科技圈内有朋友告诉“亲爱的数据”:“Hao Zhang 和 Aurick Qiao, 加盟Snowflake 后, 4个月内光速带领Snowflake AI Research 团队发布 LLM for Enterprise AI.”

新模型的推出也被视为 Snowflake 为保持与 Databricks 竞争而做出的努力,Databricks 历来在利用其数据平台为客户提供人工智能方面积极努力,硕果累累。
在公司收购 Neeva 并任命 Ramaswamy 为首席执行官之后,Snowflake 的人工智能发展直到最近才有所加速。
Snowflake Arctic 采用了一种密集的混合专家 (MoE) 架构,其参数可以细分至多 128 个专家。这些专家经过动态数据训练,时刻待命,但只会处理它们能够最有效处理的输入 token。
这意味着模型只会激活部分参数,即 4800 亿参数中的 170 亿参数,以最小的计算量实现精准的性能表现。
Snowflake 将其变体称为“Dense MoE Hybrid Transformer”。Snowflake Arctic 是稠密稀疏混合。
在稀疏 MoE 模型中,对于每个输入,只有部分专家网络处于激活状态。这可以使模型更容易训练和部署,但它也可能限制其学习复杂关联的能力。在完全激活 MoE 模型中,所有专家网络都对每个输入处于激活状态。
模型结合了 Transformer 和 MoE 架构的优点。Transformer 架构擅长处理长距离依赖关系,而 MoE 架构擅长处理专家之间的交互。
这种结构可以很容易地定制以满足特定的需求。
1.众多专家
480B参数,生成期间,用 top-2 门控来选择17B处于活跃状态。
2021年底,DeepSpeed团队证明MoE可以应用于自回归LLM,以在不增加计算成本的情况下显着提高模型质量。模型质量的提高主要取决于MoE模型中专家的数量和参数总数,以及这些专家可以组合在一起的方式数量。
2.架构和系统协同设计
即使在最强大的人工智能训练硬件上,由于专家之间的高额通信开销,用大量专家训练普通的 MoE 架构效率也非常低。然而,如果通信可以与计算重叠,则可以隐藏此开销。
根据 Snowflake 分享的基准测试,通过这种方法,Arctic 在处理企业任务方面已经表现相当出色,在多项测试中平均得分达到 65%。