

本文作者来自香港科技大学、香港科技大学(广州)、香港城市大学以及UIUC等机构。其中,港科大在读博士生陈巍昱、港城大在读博士生张霄远和港科广在读博士生林百炅为共同第一作者;林熙博士目前担任港城大博士后研究员;UIUC赵晗助理教授、港城大张青富教授以及港科大郭天佑教授为共同通讯作者。赵晗博士的研究方向主要集中在机器学习理论和可信机器学习领域,涵盖算法公平,可解释性和多任务优化等多个方向,其研究成果曾获Google Research Award。张青富教授 (IEEE Fellow) 长期致力于多目标优化的研究,所提出MOEA/D方法至今已被引用近万次,成为多目标优化经典范式之一。郭天佑教授 (IEEE Fellow) 专注于机器学习中的优化问题研究,曾获AI 2000最具影响力学者荣誉提名,并担任IJCAI-2025程序主席。
近年来,深度学习技术在自动驾驶、计算机视觉、自然语言处理和强化学习等领域取得了突破性进展。然而,在现实场景中,传统单目标优化范式在应对多任务协同优化、资源约束以及安全性 - 公平性权衡等复杂需求时,逐渐暴露出其方法论的局限性。值得注意的是,在大语言模型(LLM)与生成式 AI 系统的多维度价值对齐(Multi-Dimensional Alignment)领域,如何协调模型性能、安全伦理边界、文化适应性及能耗效率等多元目标,已成为制约人工智能系统社会应用的关键挑战。多目标优化(Multi-Objective Optimization, MOO)作为一种协调多个潜在冲突目标的核心技术框架,正在成为破解复杂系统多重约束难题的关键方法。
近日,由香港科技大学、香港科技大学(广州)、香港城市大学以及 UIUC 等团队联合发布的基于梯度的多目标深度学习综述论文《Gradient-Based Multi-Objective Deep Learning: Algorithms, Theories, Applications, and Beyond》正式上线。这篇综述从多目标算法设计、理论分析到实际应用与未来展望,全方位解析了如何在多任务场景下高效平衡各目标任务,呈现了这一领域的全景。

- 论文题目:Gradient-Based Multi-Objective Deep Learning: Algorithms, Theories, Applications, and Beyond
- 论文链接:https://arxiv.org/pdf/2501.10945v2
- 仓库链接:https://github.com/Baijiong-Lin/Awesome-Multi-Objective-Deep-Learning
背景
在深度学习中,我们常常需要同时优化多个目标:
- 多任务学习:在许多实际问题中,我们常常需要同时优化多个任务,并在不同任务之间寻求平衡,以解决它们之间的潜在冲突(例如,在分子性质预测领域,我们通常需要对一个分子预测多种性质);
- 大语言模型的多维度价值对齐:在大语言模型的训练过程中,我们期望其生成的回复能够与人类多维度的价值偏好相匹配,涵盖有用性、安全性、幽默度等多个方面;
- 资源约束、安全性、公平性等因素的权衡:在许多工业场景中,除了性能指标外,安全、能耗、延迟等实际工程指标也是需要兼顾的重要目标。
多目标优化算法旨在寻找一系列 「折中解」(也称为 Pareto 最优解),在不同目标间达到平衡,从而满足应用场景中对协同优化的要求。
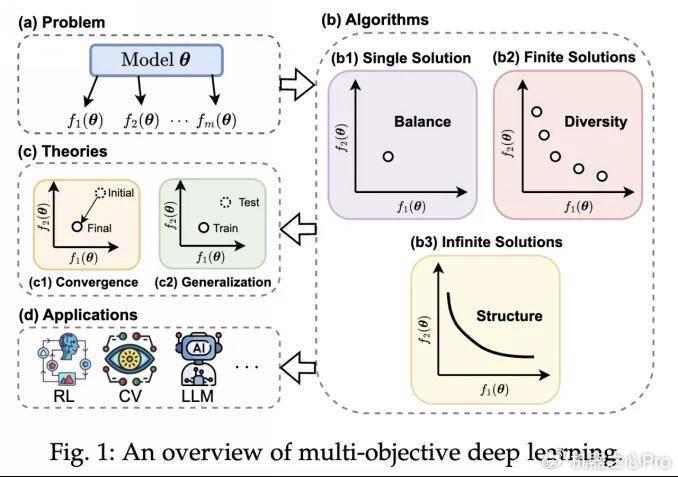
算法设计
基于梯度的多目标优化方法主要分为三类:寻找单个 Pareto 最优解的算法,寻找有限个 Pareto 最优解的算法以及寻找无限个 Pareto 最优解的算法。
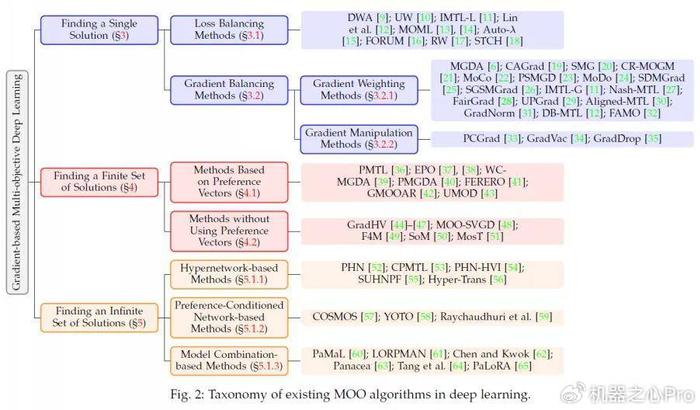
寻找单个 Pareto 最优解
在多任务学习等场景中,通常只需找到一个平衡的解,以解决任务之间的冲突,使每个任务的性能都尽可能达到最优。为此,研究者们提出了多种方法,这些方法可进一步分为损失平衡方法和梯度平衡方法。
- 损失平衡方法:通过动态计算或学习目标权重,平衡不同任务的损失。例如,动态权重平均(DWA)通过每个目标的训练损失的下降速度更新权重;不确定性加权(UW)基于每个目标的不确定性动态优化目标权重;多目标元学习(MOML)通过验证集性能自适应调整目标权重。
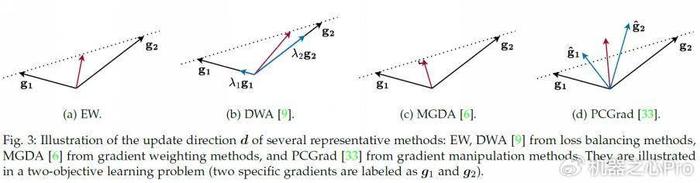
- 梯度平衡方法:通过计算多个任务梯度的 「最优平衡方向」,使模型在更新参数时能够兼顾所有任务的优化需求。这类方法又可以细分为梯度加权方法和梯度操纵方法。例如,多梯度下降算法(MGDA)通过求解优化问题找到更新方向,使该方向上的梯度更新能够最大化地减少所有任务的损失函数;PCGrad 方法将每个任务的梯度投影到与其他任务梯度冲突最小化的方向上,从而有效解决任务间的梯度冲突。
一些有代表性的方法如下图所示:
寻找有限个 Pareto 最优解
在寻找有限个 Pareto 解集时,需要同时考虑两个关键因素:解的快速收敛性(确保解迅速逼近 Pareto 最优前沿)和解集的多样性(保证解在 Pareto 前沿上的均匀分布)。目前主要有两类方法:
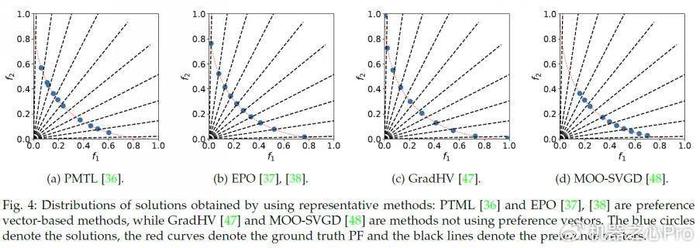
- 基于偏好向量的方法:利用偏好向量来指定特定的 Pareto 解。通过均匀分布的偏好向量,可以生成具有多样性的 Pareto 解集,覆盖 Pareto 前沿的不同区域。
- 无需偏好向量的方法:通过优化 Pareto 解集的某个指标来提高解的多样性。例如,最大化超体积(Hypervolume),使解集在目标空间中覆盖更大的区域;或者最大化最小距离,确保解集中的解彼此远离,从而提升分布均匀性。由于该类方法无需指定偏好向量,因此具有更高的适应性和灵活性。
一些有代表性的方法如下图所示:
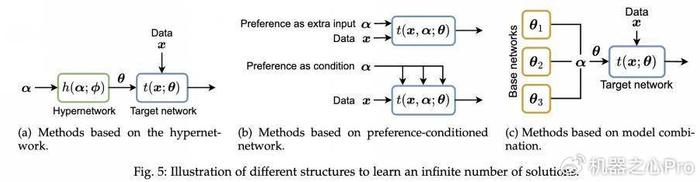
寻找无限个 Pareto 最优解
为满足用户在任一偏好下都能获得合适解的需求,研究者设计了直接学习整个 Pareto 集的方法,主要包括:
- 超网络:利用专门的网络根据用户偏好生成目标网络的参数;
- 偏好条件网络:在原模型中增加偏好信息作为额外条件;
- 模型组合:通过组合多个基模型的参数(如 PaMaL、LORPMAN 等方法)实现对所有 Pareto 解的紧凑表达。
在训练过程中,这些方法通常采用随机采样用户偏好,利用端到端的梯度下降优化映射网络参数,同时结合标量化目标或超体积最大化等策略,确保映射网络能够覆盖整个解集并实现稳定收敛。
理论分析
我们从收敛性和泛化性两个角度总结了现有的 MOO 的理论分析:
- 收敛性:针对确定性(全梯度)和随机梯度的情况,许多工作从 Pareto Stationary 角度出发,提供了收敛性证明。通过双采样、平滑移动平均以及近似求解子问题等策略,有效降低了随机梯度带来的偏差,加快了整体收敛速度,理论上可以达到单目标优化相近的收敛速率。

- 泛化性:许多工作探讨了多目标深度学习模型的泛化能力,利用 Rademacher 复杂度等工具分析了标量化方法与梯度平衡方法在未见数据上的表现。
应用与挑战
基于梯度的多目标优化方法已在多个前沿应用中展现出巨大潜力,主要包括:
- 计算机视觉(CV):应用于多任务密集预测(如语义分割、深度估计、表面法向预测),实现任务间的协同提升。
- 强化学习(RL):在多目标强化学习中,同时优化奖励、多样性和安全性指标,使智能体在复杂环境下表现更均衡。
- 神经架构搜索(NAS):兼顾模型准确性与资源消耗(如 FLOPs、参数量、延迟),寻找适合嵌入式设备的高效架构。
- 推荐系统:除准确度外,整合新颖性、多样性、用户公平等指标,为个性化推荐提供优化支撑。
- 大语言模型(LLM):(1)多任务微调:在预训练语言模型的基础上,针对多个下游任务同时微调,可以提高模型的效率和泛化能力;(2)多目标对齐:在训练阶段,通过多目标算法同时优化多个目标(如安全性、有用性、幽默性等),以使模型的输出更好地满足用户在不同方面的偏好。
尽管多目标优化方法已取得诸多进展,但仍面临一些亟待解决的问题:比如:理论泛化分析不足, 计算开销与高效性问题, 高维目标与偏好采样挑战, 分布式训练与协同优化以及大语言模型的多目标优化。
多目标算法库
我们开源了多目标深度学习领域的两大的算法库:LibMTL 和 LibMOON。
- LibMTL 是一个专为多任务学习设计的开源库,支持超过 20 种多任务算法。它在 GitHub 上已收获超过 2200 个 Star,并被机器学习顶刊《Journal of Machine Learning Research》(JMLR)接收。
- 项目地址:https://github.com/median-research-group/LibMTL
- LibMOON 是一个专注于多目标优化的开源框架,支持超过 20 种多目标算法,能够高效寻找多个 Pareto 最优解。其相关工作已被人工智能顶会 NeurIPS 2024 接收。
- 项目地址:https://github.com/xzhang2523/libmoon
结语
本综述旨在为多目标深度学习领域提供一份全面的资源整合。我们系统地梳理了从算法设计、理论分析到实际应用的各个方面,并深入探讨了未来发展面临的挑战。无论您的研究重点是多任务学习、强化学习,还是大语言模型的训练与对齐,相信都能在本文中找到有价值的见解与启发。我们也认识到,当前的工作可能未能完整涵盖该领域的所有研究成果,如果你有任何建议或补充,欢迎访问我们的 GitHub 仓库,并提交 Issue 或 Pull Request,让我们携手推动这一领域的发展,共同进步!


财经自媒体联盟













































 第一财经日报
第一财经日报  每日经济新闻
每日经济新闻  贝壳财经视频
贝壳财经视频  尺度商业
尺度商业  财联社APP
财联社APP  量子位
量子位  财经网
财经网  华商韬略
华商韬略 
4000520066 欢迎批评指正
All Rights Reserved 新浪公司 版权所有
