
当地时间 3 月 18 日,在英伟达(NVIDIA)举办年度 GPU 技术大会(GTC)上,CEO 黄仁勋登台发表了主题演讲。
两个小时的时长,从芯片架构和生成式 AI,讲到数据中心、自动驾驶和 AI 工厂,最后到个人 AI 超算和机器人,可谓是量大管饱。
老黄不仅一口气宣布了三个架构升级路线图,一波直接规划到了 2028 年,去年 GTC 登台的 BDX 小机器人也返场登台了,互动和行动似乎更加自然、灵活。
 图 | GTC 主题演讲核心内容(来源:英伟达)
图 | GTC 主题演讲核心内容(来源:英伟达)在去年的 GTC 大会上,英伟达发布了 Blackwell 架构,尽管 GPU 量产一度受阻,但近期已实现大规模生产,并在第一季度实现了数十亿美元的销售额。目前,四大云计算公司部署的 Blackwell 芯片数量是 Hopper 芯片的三倍。
今天,英伟达宣布了 Blackwell 架构的升级版 Blackwell Ultra,擅长应对 AI 推理需求。
Blackwell Ultra 以 Blackwell 架构为基础,包括了搭配 CPU 的 GB300 NVL72 机架级解决方案和仅配备 GPU 的 B300 NVL16 系统两个版本。
在表现上,GB300 的 AI 性能比上一代 GB200 高出 1.5 倍。而与 Hopper 一代相比,B300 在大语言模型上的推理速度提高了 11 倍,计算能力提高了 7 倍,内存增加了 4 倍。
老黄表示:“AI 已经取得了巨大的飞跃,推理和代理人工智能需要更高量级的计算性能。我们为这一刻设计了 Blackwell Ultra,它是一个单一的多功能平台,可以轻松高效地进行预训练、后训练和推理人工智能推理。”
Blackwell Ultra 架构将于 2025 年下半年上市,具体参数如下。
 图 | Blackwell Ultra NVL72 参数(来源:英伟达)
图 | Blackwell Ultra NVL72 参数(来源:英伟达)在这之后,英伟达宣布了其下一代 GPU 系列系统名为 Vera Rubin。这个名字来自发现了暗物质的女天文学家 Vera Rubin。
该系统有两个主要组件:一个名为 Vera 的新 CPU 和一个名为 Rubin 的新 GPU 架构。它预计于 2026 下半年问世。
从纸面参数来看,它将全方位超越 Blackwell Ultra,关键性能几乎都是两倍以上的提升。
 图 | 下一代架构 Vera Rubin NVL144(来源:英伟达)
图 | 下一代架构 Vera Rubin NVL144(来源:英伟达)这还没完,接下来亮相的产品(ppt)是 Vera Rubin 的下一代,Vera Rubin Ultra NVL576。纸面性能又是一波暴涨。
 图 | 下一代架构升级版 Vera Rubin Ultra NVL576(来源:英伟达)
图 | 下一代架构升级版 Vera Rubin Ultra NVL576(来源:英伟达)“Vera Rubin Ultra 拥有 250 万个零件,并连接到 576 个 GPU。”老黄表示。不过他也承认有些规划“过于超前”,但“这就是我们向前发展的速度”。
反过来看,我们也再一次见识了老黄的刀法,产品还没出来,就已经想好怎么刀了。
 图 | Hopper、Blackwell 和 Rubin 性能对比(来源:英伟达)
图 | Hopper、Blackwell 和 Rubin 性能对比(来源:英伟达)那你可能要问了,Rubin Ultra 之后是什么呢?
至少名字英伟达想好了,以数学家理查德·费曼(Richard Feynman)命名的费曼架构,预计在 2028 年问世。
 图 | 2025-2028 架构规划路线图(来源:英伟达)
图 | 2025-2028 架构规划路线图(来源:英伟达)介绍完了 GPU 架构,老黄谈到了其他的英伟达产品线。
首先是以太网设备升级。改善网络本身将有助于使 AI 的工作过程更加顺畅,为此英伟达宣布推出新的 Spectrum-X 硅光子以太网交换机,该交换机每端口可提供 1.6 太比特每秒的速度,从而为 AI 工厂节省 3.5 倍的能源并提高 10 倍的弹性。
该产品是英伟达 Spectrum-X 光子以太网和 Quantum-X 光子 InfiniBand 平台的一部分。
英伟达表示,与传统方法相比,它们的光学技术创新使用了更少的激光器(减少 4 倍),还能实现 3.5 倍的能效、63 倍的信号完整性、10 倍的大规模网络弹性和 1.3 倍的部署速度提升。
“AI 工厂是一种规模极大的新型数据中心,网络基础设施必须重新改造才能跟上步伐。通过将硅光子学直接集成到交换机中,英伟达打破了超大规模和企业网络的旧有限制,为百万 GPU AI 工厂打开了大门。”老黄表示。
 图 | 硅光子芯片(来源:英伟达)
图 | 硅光子芯片(来源:英伟达)接下来,老黄介绍了新款 DGX Spark 和 DGX Station 个人 AI 计算机,他将其描述为“AI 时代的超级计算机”。
这两款超级计算机均由 Grace Blackwell 平台支持,旨在“让 AI 开发人员、研究人员、数据科学家和学生在桌面上对大模型进行原型设计、微调和推理”。
Spark 搭载了 GB10 Blackwell 芯片,提供第五代 Tensor Core 和 FP4 支持,具有 128GB 统一内存和高达 4TB 的 NVMe SSD 存储,可以提供“高达每秒 1 千万亿次运算的 AI 计算。”
体积更大的 DGX Station 可以容纳英伟达刚刚宣布的功能更强大的 GB300 Blackwell Ultra 芯片,可提供“每秒 20 千万亿次运算的 AI 性能和 784GB 的统一系统内存”。
Spark 将于今日开始预订,售价 3000 美元起。DGX Station 目前尚未定价。
 图 | DGX Spark 和 Station(来源:英伟达)
图 | DGX Spark 和 Station(来源:英伟达)随后老黄宣布了开源推理模型系列,英伟达 Llama Nemotron Reasoning,一种“任何人都可以运行”的 AI 模型。
顾名思义,Llama Nemotron 基于 Meta 的开源 Llama 模型。英伟达通过算法对模型进行调整,以优化计算要求,同时保持准确性。
它还利用合成数据应用了复杂的后训练技术。训练涉及 36 万小时 H100 推理时间和 4.5 万小时人工注释时间,以增强推理能力。
整个系列包括三种模型尺寸:
-Nemotron Nano:针对边缘和较小部署进行了优化,同时保持了较高的推理精度。
-Nemotron Super:在单数据中心 GPU 上实现最佳吞吐量和准确性的平衡。
-Nemotron Ultra:专为在多 GPU 数据中心环境中实现最大“代理精度”而设计。
作为英伟达 NIM 微服务的一部分,这套模型可以在任何平台上运行。
 图 | Llama Nemotron 系列模型(来源:英伟达)
图 | Llama Nemotron 系列模型(来源:英伟达)压轴登场的是一系列机器人技术。最重要的是 Isaac GR00T N1,世界上第一个开放、完全可定制的通用人形推理和技能基础模型。
其他新技术亮点包括模拟框架和蓝图,例如用于生成合成数据的 Isaac GR00T 蓝图,以及由 DeepMind 和迪士尼研究部门共同开发的专为开发机器人而构建的开源物理引擎 Newton。
 图 | 机器人与人类协作(来源:英伟达)
图 | 机器人与人类协作(来源:英伟达)据英伟达介绍,GR00T N1 基础模型采用双系统架构,其灵感来自人类认知原理。
“系统 1”是一种快速思考的行动模型,反映了人类的反应或直觉。“系统 2”则是一种慢速思考的模型,用于深思熟虑、有条不紊的决策。
在视觉语言模型的支持下,系统 2 可以推理其环境和收到的指令,从而规划行动。然后,系统 1 将这些计划转化为精确、连续的机器人动作。
GR00T N1 可以实现常见任务,例如抓取、用一只或两只手移动物体,以及将物品从一只手转移到另一只手,或者执行需要技能组合的多步骤任务。
开发人员和研究人员可以使用真实或合成数据对 GR00T N1 进行后期训练,以适应特定的人形机器人或任务。
英伟达还将与谷歌 DeepMind 和迪士尼研究中心合作开发 Newton,这是一个开源物理引擎,可让机器人学习如何更精确地处理复杂任务。
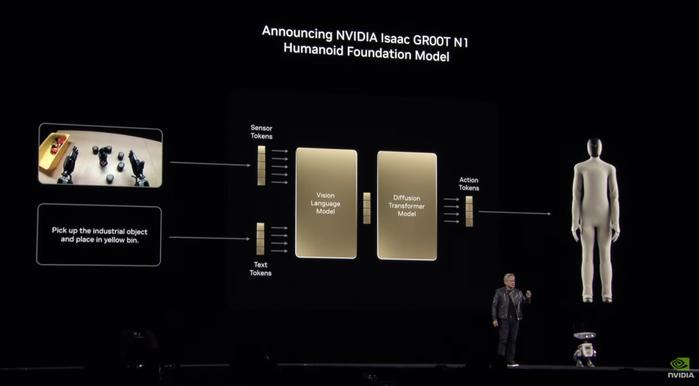 图 | GR00T N1 开源(来源:英伟达)
图 | GR00T N1 开源(来源:英伟达)Newton 基于英伟达 Warp 框架构建,将针对机器人学习进行优化,并与 DeepMind 的 MuJoCo 和英伟达 Isaac Lab 等模拟框架兼容。此外,三家公司还计划让 Newton 使用迪士尼的物理引擎。
迪士尼研究公司将成为首批使用 Newton 来改进其机器人角色平台的公司之一,为下一代娱乐机器人提供动力。
在 GTC 大会的最后,去年 GTC 就曾亮相的可爱 BDX 机器人再次登台,其动和行动似乎更加自然、灵活了,赚足了眼球。
 图 | 小机器人登台(来源:英伟达)
图 | 小机器人登台(来源:英伟达)最后值得一提的是,当地时间 3 月 20 日,英伟达将会举办首个“量子日(Quantum Day)”活动,召集行业专家共同思考企业在未来几十年对量子计算的期望,并规划出有价值的量子应用之路。这将是英伟达在量子计算领域迈出的重要一步。
参考资料:
https://nvidianews.nvidia.com/news/nvidia-isaac-gr00t-n1-open-humanoid-robot-foundation-model-simulation-frameworks
https://nvidianews.nvidia.com/news/blackwell-ultra-dgx-superpod-supercomputer-ai-factories
https://nvidianews.nvidia.com/news/nvidia-announces-dgx-spark-and-dgx-station-personal-ai-computers
https://www.nvidia.com/gtc/keynote/


财经自媒体联盟













































 第一财经日报
第一财经日报  每日经济新闻
每日经济新闻  贝壳财经视频
贝壳财经视频  尺度商业
尺度商业  财联社APP
财联社APP  量子位
量子位  财经网
财经网  华商韬略
华商韬略 
4000520066 欢迎批评指正
All Rights Reserved 新浪公司 版权所有
