
作者|ZackSock
来源 | 新建文件夹X(ID:ZackSock)
头图 | CSDN下载自视觉中国
前言
爬虫一直是Python的一大应用场景,差不多每门语言都可以写爬虫,但是程序员们却独爱Python。之所以偏爱Python就是因为她简洁的语法,我们使用Python可以很简单的写出一个爬虫程序。本篇博客将以Python语言,用几个非常简单的例子带大家入门Python爬虫。
网络爬虫
如果把我们的因特网比作一张复杂的蜘蛛网的话,那我们的爬虫就是一个蜘,我们可以让这个蜘蛛在网上任意爬行,在网中寻找对我们有价值的“猎物”。
首先我们的网络爬虫是建立在网络之上的,所以网络爬虫的基础就是网络请求。在我们日常生活中,我们会使用浏览器浏览网页,我们在网址栏输入一个网址,点击回车在几秒时间后就能显示一个网页。

我们表面上是点击了几个按钮,实际上浏览器帮我们完成了一些了的操作,具体操作有如下几个:
1.向服务器发送网络请求
2.浏览器接收并处理你的请求
3.浏览器返回你需要的数据
4.浏览器解析数据,并以网页的形式展现出来
我们可以将上面的过程类比我们的日常购物:
1.和老板说我要杯珍珠奶茶
2.老板在店里看看有没有你要的东西
3.老板拿出做奶茶的材料
4.老板将材料做成奶茶并给你
上面买奶茶的例子虽然有些不恰当的地方,但是我觉得已经能很好的解释什么是网络请求了。


有些时候网站的反爬虫做的比较差,我们可以直接在浏览器中找到它的API,我们通过API可以直接获取我们需要的数据,这种相比就要简单许多。
简单的爬虫
简单的爬虫就是单纯的网络请求,也可以对请求的数据进行一些简单的处理。Python提供了原生的网络请求模块urllib,还有封装版的requests模块。相比直线requests要更加方便好用,所以本文使用requests进行网络请求。
3.1、爬取一个简单的网页
在我们发送请求的时候,返回的数据多种多样,有HTML代码、json数据、xml数据,还有二进制流。我们先以百度首页为例,进行爬取:
import requests
# 以get方法发送请求,返回数据
response = requests.get('http://www.baidu.com')
# 以二进制写入的方式打开一个文件
f = open('index.html', 'wb')
# 将响应的字节流写入文件
f.write(response.content)
# 关闭文件
f.close()
下面我们看看爬取的网站打开是什么样子的:

这就是我们熟悉的百度页面,上面看起来还是比较完整的。我们再以其它网站为例,可以就是不同的效果了,我们以CSDN为例:
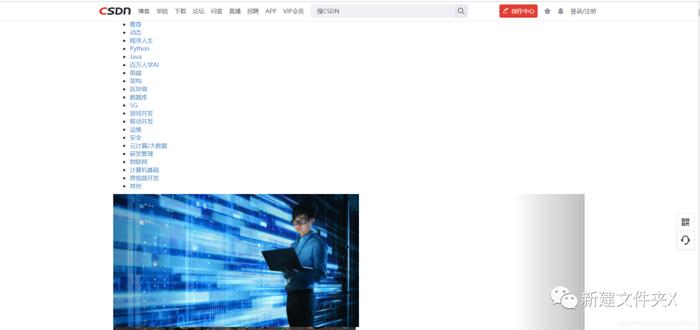
可以看到页面的布局已经完全乱了,而且也丢失了很多东西。学过前端的都知道,一个网页是由html页面还有许多静态文件构成的,而我们爬取的时候只是将HTML代码爬取下来,HTML中链接的静态资源,像css样式和图片文件等都没有爬取,所以会看到这种很奇怪的页面。
3.2、爬取网页中的图片
首先我们需要明确一点,在爬取一些简单的网页时,我们爬取图片或者视频就是匹配出网页中包含的url信息,也就是我们说的网址。然后我们通过这个具体的url进行图片的下载,这样就完成了图片的爬取。我们有如下url:https://img-blog.csdnimg.cn/2020051614361339.jpg,我们将这个图片url来演示下载图片的代码:
import requests
# 准备url
url = 'https://img-blog.csdnimg.cn/2020051614361339.jpg'
# 发送get请求
response = requests.get(url)
# 以二进制写入的方式打开图片文件
f = open('test.jpg', 'wb')
# 将文件流写入图片
f.write(response.content)
# 关闭文件
f.close()
可以看到,代码和上面网页爬取是一样的,只是打开的文件后缀为jpg。实际上图片、视频、音频这种文件用二进制写入的方式比较恰当,而对应html代码这种文本信息,我们通常直接获取它的文本,获取方式为response.text,在我们获取文本后就可以匹配其中的图片url了。我们以下列http://topit.pro为例:
importre
importrequests
# 要爬取的网站
url = 'http://topit.pro'
# 获取网页源码
response = requests.get(url)
# 匹配源码中的图片资源
results = re.findall("[\\s\\s]+?src=\"(.+?)\"",>
# 用于命名的变量
name =
# 遍历结果
forresult in results:
# 在源码中分析出图片资源写的是绝对路径,所以完整url是主站+绝对路径
img_url = url+result
# 下载图片
f = open(str(name) + '.jpg', 'wb')
f.write(requests.get(img_url).content)
f.close()
name+= 1
上面我们就完成了一个网站的爬取。在匹配时我们用到了正则表达式,因为正则的内容比较多,在这里就不展开了,有兴趣的读者可以自己去了解一下,这里只说一个简单的。Python使用正则是通过re模块实现的,可以调用findall匹配文本中所有符合要求的字符串。该函数传入两个参数,第一个为正则表达式,第二个为要匹配的字符串,对正则不了解的话只需要知道我们使用该正则可以将图片中的src内容拿出来。
使用BeautifulSoup解析HTML
BeautifulSoup是一个用来分析XML文件和HTML文件的模块,我们前面使用正则表达式进行模式匹配,但自己写正则表达式是一个比较繁琐的过程,而且容易出错。如果我们把解析工作交给BeautifulSoup会大大减少我们的工作量,在使用之前我们先安装。
4.1、BeautifulSoup的安装和简单使用
我们直接使用pip安装:
pip install beautifulsoup4
模块的导入如下:
from bs4 import BeautifulSoup
下面我们就来看看BeautifulSoup的使用,我们用下面HTML文件测试:
htmllang="en">
head>
metacharset="UTF-8">
title>Titletitle>
head>
body>
imgclass="test"src="1.jpg">
imgclass="test"src="2.jpg">
imgclass="test"src="3.jpg">
imgclass="test"src="4.jpg">
imgclass="test"src="5.jpg">
imgclass="test"src="6.jpg">
imgclass="test"src="7.jpg">
imgclass="test"src="8.jpg">
body>
html>
上面是一个非常简答的html页面,body内包含了8个img标签,现在我们需要获取它们的src,代码如下:
from bs4 import BeautifulSoup
# 读取html文件
f = open('test.html', 'r')
str = f.read()
f.close()
# 创建BeautifulSoup对象,第一个参数为解析的字符串,第二个参数为解析器
soup = BeautifulSoup(str, 'html.parser')
# 匹配内容,第一个为标签名称,第二个为限定属性,下面表示匹配class为test的img标签
img_list = soup.find_all('img', {'class':'test'})
# 遍历标签
for img in img_list:
# 获取img标签的src值
src = img['src']
print(src)
解析结果如下:
1.jpg
2.jpg
3.jpg
4.jpg
5.jpg
6.jpg
7.jpg
8.jpg
正好就是我们需要的内容。
4.2、BeautifulSoup实战
我们可以针对网页进行解析,解析出其中的src,这样我们就可以进行图片等资源文件的爬取。下面我们用梨视频为例,进行视频的爬取。主页网址如下:https://www.pearvideo.com/。我们右键检查可以看到如下页面:

import requests
from bs4 import BeautifulSoup
# 主站
url = 'https://www.pearvideo.com/'
# 模拟浏览器访问
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'
}
# 发送请求
response = requests.get(url, headers=headers)
# 获取BeautifulSoup对象
soup = BeautifulSoup(response.text, 'html.parser')
# 解析出符合要求的a标签
video_list = soup.find_all('a', {'class':'actwapslide-link'})
# 遍历标签
for video in video_list:
# 获取herf并组拼成完整的url
video_url = video['href']
video_url = url + video_url
print(video_url)
输出结果如下:
https://www.pearvideo.com/video_1674906
https://www.pearvideo.com/video_1674921
https://www.pearvideo.com/video_1674905
https://www.pearvideo.com/video_1641829
https://www.pearvideo.com/video_1674822
我们只爬取一个就好了,我们进入第一个网址查看源码,发现了这么一句:
var contId="1674906",liveStatusUrl="liveStatus.jsp",liveSta="",playSta="1",autoPlay=!1,isLiving=!1,isVrVideo=!1,hdflvUrl="",sdflvUrl="",hdUrl="",sdUrl="",ldUrl="",srcUrl="https://video.pearvideo.com/mp4/adshort/20200517/cont-1674906-15146856_adpkg-ad_hd.mp4",vdoUrl=srcUrl,skinRes="//www.pearvideo.com/domain/skin",videoCDN="//video.pearvideo.com";
其中srcUrl就包含了视频文件的网站,但是我们肯定不能自己一个网页一个网页自己找,我们可以使用正则表达式:
import re
# 获取单个视频网页的源码
response = requests.get(video_url)
# 匹配视频网址
results = re.findall('srcUrl="(.*?)"', response.text)
# 输出结果
print(results)
结果如下:
['https://video.pearvideo.com/mp4/adshort/20200516/cont-1674822-14379289-191950_adpkg-ad_hd.mp4'
然后我们就可以下载这个视频了:
withopen('result.mp4', 'wb') as f:
f.write(requests.get(results[], headers=headers).content)
完整代码如下:
import re
import requests
from bs4 import BeautifulSoup
# 主站
url = 'https://www.pearvideo.com/'
# 模拟浏览器访问
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'
}
# 发送请求
response = requests.get(url, headers=headers)
# 获取BeautifulSoup对象
soup = BeautifulSoup(response.text, 'html.parser')
# 解析出符合要求的a标签
video_list = soup.find_all('a', {'class':'actwapslide-link'})
# 遍历标签
video_url = video_list[0]['href']
response = requests.get(video_url)
results = re.findall('srcUrl="(.*?)"', response.text)
with open('result.mp4', 'wb') as f:
f.write(requests.get(results[0], headers=headers).content)
到此我们就从简单的网页到图片再到视频实现了几个不同的爬虫。


