
文/陈仪香,张民,张敏
本报告分为三个方面,首先简要介绍人工智能的发展史;然后重点阐述人工智能的可信性;最后介绍华东师范大学可信智能实验室在人工智能可信性方面的研究工作进展。
一、人工智能简史
提到人工智能不能不提英国的数学家、逻辑学家图灵,1936年他提出了一种理想计算机的数学模型,称之为图灵机。1950年提出了著名的“图灵实验”:让人和计算机分处两个不同的房间里,并互相对话,如果作为人的一方不能判断对方是人还是计算机,则那台计算机就达到了人的智能。这是对智能的一个明确定义。
1956年夏天美国数学家、计算机科学家McCarthy 和其他学者联合发起了在美国达德茅斯大学召开的世界上第一次人工智能学术大会,会上正式决定使用人工智能 (artificial intelligence, AI) 一词来概括这个研究方向。1956 年成为了人工智能作为一门独立的研究领域正式诞生的元年,而 McCarthy本人在美国也常常被人们看作是“人工智能之父”。McCarthy1958年发明Lisp编程语言(一种基于逻辑的函数式设计语言,至今仍活跃在人工智能领域),1971年因对AI的贡献获得图灵奖。
人工智能有各种版本的定义,比较正式的是全国科学技术名词审定委员会2018年出版的《计算机科学技术名词》(第三版)给出的定义:解释和模拟人类智能、智能行为及其规律的学科,主要任务是建立智能信息处理理论,进而设计可展现近似人类智能行为的计算机系统。2000 年陆汝钤院士在其专著《人工智能》(科学出版社出版)中提到,人工智能研究不仅与对人的思维研究密切相关,而且与许多其他学科密切相关。也就是人工智能是一个综合学科的研究。
目前,我国把人工智能提到了一个非常重要的位置,把它作为推动数字经济、智能社会一个重要的推动技术、理论和科学的手段。
2019年谭铁牛院士在《求是》杂志上发表的一篇文章《人工智能的历 史、现状和未来》(https://www.cas.cn/zjs/201902/t20190218_4679625.shtml),他将人工智能的三次高潮划分成六个阶段。从图 1 中可见,第一次人工智能高潮是人工智能诞生后的十年,其代表性成果是跳棋程序和机器定理证明。以吴文俊先生为代表的我国科学家在机器定理证明领域取得了很好的研究成果。但机器翻译闹出的笑话,以及机器无法证明两个连续函数之和还是连续函数,使人工智能进入了10年的反思发展期。专家系统成功地应用于医疗、化学、地质等领域推动了人工智能第二次高潮——应用发展期的出现。专家系统的核心技术是知识库和推理。常识性知识的缺乏,以及推理方法的单一使人工智能进入了第二个低迷期。经过近10年的探索,分布计算的应用推动了人工智能进入了稳步发展期,典型事件是深蓝超级计算机——深蓝世界象棋战胜卡斯帕罗夫,成为当时全球轰动的事件。随后几年人工智能进入了蓬勃发展期,也迎来了第三次高潮期。典型案例是以深度神经网络为代表的机器学习推动了人工智能的广泛应用,其典型例子就是图像分类和无人驾驶。围棋机器人AlphaGo战胜了韩国职业围棋手李世石,更奠定了机器学习在人工智能的地位。

人工智能自1956诞生到2020年,历时65年,经历了三次高潮和两次低潮,表现出像其他学科的发展一样,高低起伏螺旋式上升。
从2020年开始,我们认为人工智能进入了沉思发展期。我们想一想,现在人工智系统是否能呈现出图灵定义的智能?现在的图像分类和识别是否具有抗干扰性?我们敢不敢使用安装在汽车里的无人驾驶系统?我们能否相信像人一样智慧的人工智能系统?这就是人工智能的可信性问题。
如果按照人工智能10年为一个周期,2030年应该能解决这些问题。所以我们在谭铁牛院士提出的人工智能发展六个阶段后面,增加了沉思发展期。人工智能有三次高潮已被公认,目前在处于第三次高潮下落期,我们应该沉思一下,人造的具有人类智慧的计算机系统能否可信?
换句话说,人工智能是否可信?我们从哪几个方面来看这个问题?比如任务系统为什么要这么工作,它的原因是什么?它的鲁棒性是什么?能不能抗干扰、抗对抗?是否具有公平性?是否符合伦理?
二、人工智能可信性
基于深度神经网络的图像分类是人工智能比较成功的典型案例。图像分类是在一个有固定的分类标签集合上,对于输入的图像,从分类标签集合中找出一个分类标签,最后把这个分类标签分配给该输入图像,就确立了这个输入图像类别。这个过程相当于我们在教幼儿园孩子从图学习识别小猫、小狗、狮子、兔子、鸡和鱼等动物。图 2 示出的是一台经典计算机,而且是一个白板,说明它是一个无知的计算机系统,我们要通过不断训练与学习,通过图片的输入告诉它这是什么;通过多遍学习与训练,认识这张图片后就会回答。然而如果给一张不打标签图片,它能识别出来吗?经过学习与训练,成人正确认识这些图片没问题,但是如果给两三岁小孩识别可能就有问题了。因此说,机器学习的水平也就是人类两三岁小孩的水平,这是不行的。

然而真是这样?大家都知道盲人摸象。正常人的眼睛识别大象是从整体来看,但盲人摸象是局部看象:一人一象。这正是“众盲摸象,各说异端,忽遇明眼人又作么生?”现在的神经网络学习如果像盲人摸象那样,问题就严重了。
2016年1月20日,在京港澳高速邯郸段,一辆特斯拉Model S与前方道路清扫车发生追尾事故,造成特斯拉车辆驾驶员死亡。交警认定,特斯拉驾驶员负主要责任。但经过一年多的调查审理有了新的进展,特斯拉方面确认在车祸发生时,车辆处于“自动驾驶”状态(https://www.sohu.com/a/228965384_451144)。造成追尾事故可能是自动驾驶的汽车没有能识别出前方的道路清扫车,也可能是识别出来了但制动刹车不及时造成的追尾。
2017年美国学者Evan Ackernab在IEEE Spetrum上发表论文指出,深度神经网络在图像识别方面取得了巨大成功,但容易受到攻击。他举了一个例子。在交通标志牌STOP上进行了简单的涂鸦,交通标志识别系统识别后输出的是限速45英里。人类绝不会出现这样的错误。造成这种结果的原因是在其样本库里没有涂过鸦的交通标志STOP,所以识别系统不认识它,很可能随便给出一个标签。如果把这个道路交通标志识别系统放到无人驾驶系统里,谁敢使用?
2018年3月18日晚上10点左右,美国亚利桑那州一名女子被优步Uber自动驾驶汽车撞伤,行人在送往医院后不治身亡。事故发生地警察表示,初步调查显示,在这起交通事故中,优步可能不存在过错。但一年后,2019年11月7日,美官方公布了全球首例无人车致死事故的更多细节。车祸前 5.6秒时车辆就已经检测到了行人,但是系统把她错误识别为汽车。车祸前5.2秒,汽车的自动驾驶系统又把她归类为“其他”,认为她是不动的物体,并不妨碍车辆行驶。系统对物体的分类发生了混乱,在“汽车”和“其他”之间摇摆不定,浪费了大量宝贵的时间。(https://baike.Baidu.com/item/3·18)
从上面的示例可以看到,人工智能能做很多事情。在正常情况能以很高的概率给出正确的结果,但在异常情况下不知如何处理了?这点没有体现人类的智慧。
三、人工智能可信性研究
2019年,何积丰院士在一个论坛上作了一个《安全可信人工智能》报告(同时报告发表在《信息安全与通信保密》杂志上)指出,从可信人工智能的特征分析,可信人工智能应具备与人类智能类似的特质,如鲁棒性、自我反省性、自适应性和公平性。同时,何院士在报告里还提到欧盟制定的可信人工智能五个基本准则:福祉原则——向善、不作恶原则——无害、自治原则——人类能动性、公正原则——公平性、可解释性原则——透明运行。我们总结后给出人工智能可信性五角形模型,如图3所示。

下面重点阐述鲁棒性、公平性和解释性问题。
(一)鲁棒性
神经网络的鲁棒性就是指神经网络是否能在允许的扰动范围内仍然对输入做出相同的判断。但是目前深度神经网络做不到这一点,实验表明一个肉眼无法察觉的扰动可能会使神经网络做出截然不同的判断。近年来,越来越的学者开始研究如何利用形式化方法验证神经网络是否满足鲁棒性。
神经网络的验证可借助程序验证中的 Hoare Logic表示为一个三元组(P,f,Q), 其中P为前置条件、f为神经网络、Q为后置条件。对于鲁棒性,可将P定义为一个二元谓词

, 表示两个输入x,x'在lp范数下的距离小于或等于
;Q同样定义为一个二元谓词

, 表示神经网络f在两个输入x、x'上的分类结果相同。证明神经网络f满足鲁棒性,等价于证明如下公式成立

上式可理解为对于任意的一个输入x,假设x'是在x上的任意一个合法扰动,那么x、x'的分类结果相同。由于此式的证明非常困难,现在大部分研究多假设x为一个固定值,验证f针对x是否是鲁棒的。
本文作者在ISSRE’21中设计了一个基于证伪的神经网络鲁棒性验证算法(见图4)。该算法是寻找输入对 (x,x') 满足

。遍历所有可能的标签是否满足不等式。改进后的方法是,先对所有非目标遍历所有可能的标签是否满足不等式进行排序。排序的准则是将最有可能被误判的标签放在前面,然后按照顺序查看上面的不等式是否成立。
假设
为目标标签,则
依次为最有可能及次有可能被误分的标签。根据输入的数据及扰动区间,计算每个非目标标签对应的概率区间。再计算每个区间的上界与目标标签概率区间的下界的重合度,重合度越大,表示被误判的可能性就越大。
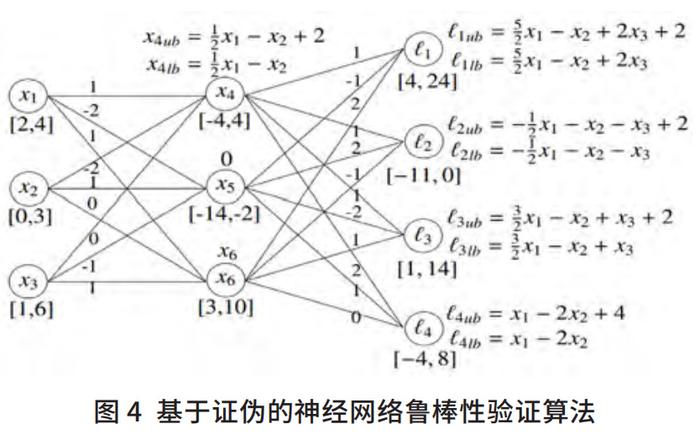
把提出的方法应用于最新的四个验证工具MipVerify、Neurify、DeepZ和DeepPoly,结果表明在验证效率方面有200余倍的提升(见图5)。所提方法同样适用于卷积神经网络验证。

(二)公平性
2019年美国社会心理学家Amber Cazzell在https://hackernoon.com/ 上发表文章指出,神经网络在样本训练与学习中缺乏公平性。用统计数据预测亚马逊招聘应用中,出现了AI招聘系统对男性求职者更青睐的现象,这是对性别的歧视;使用个人行为数据预测累犯概率时,黑人被预测为累犯的概率比白人高,这是对种族的歧视。这些带有偏见的现实应用会加剧社会不平等,造成更严重的社会危害。
神经网络的公平性是指神经网络在计算时保证不论属于哪个群体,所有人都能遵守统一计算标准,给出公平的计算结果。神经网络是否满足公平性?如何验证?
定义 ( 个体歧视样例 )假设神经网络模型N,其数据集是X、属性集合为A,P表示是A的一个子集,定义为敏感属性集合,而A\P则为非敏感属性集合。如果存在一个样本
满足以下条件,则样本
是神经网络模型N的一个个体歧视样例:

输入对 (x,x') 则称为一组个体歧视样例对。
定义 ( 个体公平性 )对于任意样本
和
,若满足

和

,则有

,这样神经网络模型N样本数据集X上满足个体公平性。
个体公平性测试问题定义:对于一个给定的训练集X和一个神经网络模型N,尝试通过扰动X中的样本,尽可能快地生成尽可能多的个体歧视样例,并利用生成的个体歧视样例有效降低原模型的歧视程度。
本文作者在ISSTA21提出一种神经网络模型的公平性测试框架EIDIG (efficient individual discrimination instance generator) ,如图6所示,主要包括生成个体歧视样例和消除歧视两个部分。

从图7所示的训练结果看到,EIDIG与最好方法ADF 比,总体上,从搜索效率角度来看,当搜索的最大尝试次数固定时,EIDIG生成个体歧视样例的速度比 ADF多检验了24.75%的搜索空间,比ADF多生成了 25.78%的个体歧视样例。而EIDIG将神经网络模型的个体公平性提升了81.15%,明显优于ADF的72.97%。

(三)可解释性
可解释性就是智能系统决策过程可被人类理解。智能系统如何决策?为何这么决策?我们认为可解释性可以使用因果关系模型来建立。因果关系模型:A(原因)→ B(结果)。比如,弗朗西斯·培根说过的知识就是力量:“知识→力量”;现代语中的知识→改变命运等。
表情识别是机器学习一个重要领域,一般的方法是在样本数据库中对样本进行标注,通过机器学习算法训练分类模型,通过测试数据确立分类模型。微表情是当人们试图隐藏内心某种真实情感时,所泄漏的短暂面部表情变化。微表情动作转瞬即逝,多数人在日常生活中往往会忽视它的存在,但它作为一种高效的行为性线索,对了解人类内心世界真实感情的变化具有重要意义。微表情分为微笑、惊讶、愤怒、伤心、紧张五类,如何识别它们?
我们微表情识别的解决方法是,首先建立数学模型,给出阈值;通过样本数据获得阈值的合理值;最后依据这个合理值确立分类模型,建立微表情分类的因果关系模型,提供微表情识别的解释过程。
人脸表情识别通常建立在人脸的68个特征点上(见图8)。微表情识别可从中选取人脸局部特征点,进行建模识别。我们选取眉毛特征点18~27,眼睛特征点37~46,嘴特征点49~68。根据这些特征点建立眉毛、眼睛、嘴唇的微表情变化公式。

眉毛微表情变化:记特征点22(左眉头)为A点,特征点23(右眉头)为B点,N是特征点31(鼻梁稳定点)为N点,计算AN和BN的欧式距离:

阈值:测验者与自己1分钟的平均距离值进行比较,可以把眉毛的变化分成皱眉(小于平均值)、扬眉(大于平均值)和正常(等于平均值)三类。
眼睛微表情变化:记左眼特征点37为P1、38为P2、39为P3、40为P4、41为P5、42为P6。计算上下眼皮距离之和与眼睛长度之比

。通过机器学习,学到了眼睛微表情变化阈值,依据这个阈值将眼睛微表情变化分为睁大眼(EAR≥0.28)、正常(0.2 ≤ EAR
嘴唇微表情识别:计算嘴唇特征点63(上嘴唇)和 67(下嘴唇)的欧式距离D,求出D的最大值DMAX,然后计算D与DMAX 的比RD,基于机器学习学得RD阈值,再依据这个阈值将嘴的微表情分成张大嘴(RD≥0.4)、咪咪嘴(0
嘴角微表情识别:计算左嘴唇L(特征点49)、右嘴唇R(特征点 55)与鼻梁稳定点N(特征点31)组成三角形的角度∠NLR 和∠NRL 的值。每个人鼻梁与嘴角的基础夹角通常不同,首先针对于不同的受测者,其需事先提供约1分钟嘴部处于正常状态的视频,统计视频中鼻梁与嘴角夹 角值,分别计算和记录∠NLR 和∠NRL 的平均值。当大于平均值时分类为嘴角上扬,当小于平均值时分类为嘴角下压。
一个微表情的出现是由一个或多个面部局部区域的变化组成的。将眼睛、嘴巴、眉毛相应的动作状态适当组合,可以建立微表情识别因果关系模型(见图9)。例如,微笑:眯眯眼 + 咪咪嘴 + 嘴角上扬,惊讶:睁大眼 + 扬眉,伤心:咪咪眼 + 嘴角下压,愤怒:眯眯眼 + 闭嘴 + 扬眉。

我们实验室开发一个微表情识别工具,可以实时地识别检测者的微表情变化(见图10)。

四、结束语
人工智能自诞生时起,历时近70年,经历了三次高潮,现在进入沉思发展期,其特征是关注人工智能的可信性。本报告总结归纳出人工智能可信性的六个属性,这些是人工智能可信性研究的基础,随着研究的深入,更多人工智能可信性属性会被提出。此外介绍了华东师范大学可信智能实验室在人工智能的可信性研究工作取得的进展。但本报告的初衷是期待着年轻的科学工作者投入到人工智能可信性的研究,使更加创新的人工智能可信性研究成果涌出,更加可信的人工智能产品惠及社会。
(参考文献略)

选自《中国人工智能学会通讯》
2022年第12卷第6期
演讲实录
头条号入驻


4000520066 欢迎批评指正
All Rights Reserved 新浪公司 版权所有
