
说一个很多人不太信的冷知识,中国本土企业在类似ChatGPT的研发中,技术并不算差,走的也不算慢。
除了百度即将推出的文心一言,阿里、腾讯、华为等大厂均有布局。
OpenAI成功的秘诀,并不是技术上有多少代差的领先,而是瞄准了一个方向,大力出奇迹的结果。
当这个方向被证实可以成功后,后面的追随者就可以蜂拥而至了,而这恰恰是中国企业最擅长的。
尽管这种模式被人诟病为“缺乏创新”,但几乎所有的高端科技被中国企业掌握后,就变成了全球人民触手可及的白菜价产品,这本身就是一种伟大的创新。
大模型也是类似。
2021年初的时候,全球有不少大厂在研究大模型,并推出了自己的阶段性产品。在那个时候,GPT并不是明显的一骑绝尘的那一个。
Facebook、Google、智源(清华旗下)、达摩院(阿里旗下)、鹏城实验室(华为旗下)等企业的作品都很出色。
甚至广大吃瓜群众一度认为Google的BERT才是未来。
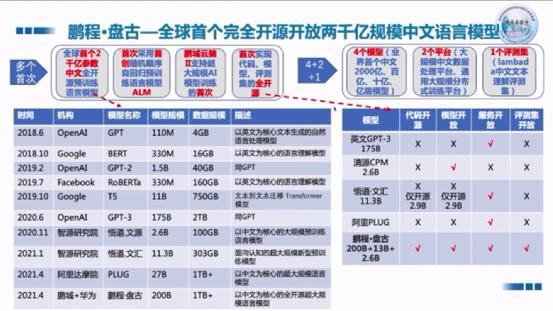
2021年,鹏程发布了盘古模型,并进行了开源(PS,智源的ChatGLM也进行了开源,其最简化的版本在消费级显卡就可以单机跑起来,支持纯国产化硬件平台,在算力卡受到制约的时候,国产硬件可以聚集规模优势,所以星空君很看好这个模型,不过最近搞了一块3060,只有12G显存,距离ChatGLM的13G最低显存要求还有一步之遥)。
从时间线上来看,和ChatGPT相比,盘古大约落后不到两年的样子。
后面差的,是烧钱上算力进行训练。
为什么华为会搞大模型?
先从OpenAI搞大模型说起,是谁成就了ChatGPT?微软。
除了投钱买显卡外,微软还提供了Azure云计算资源。
训练数据需要大量的云资源,从ChatGPT对编程的过于熟练的程度看(训练了GitHub全部代码?),不负责任的猜想,GPT模型的训练,甚至有可能基于某种法律的灰色地带使用了云端用户的数据。
智源剑走偏锋,用的是小算力模式。
阿里达摩院就不多说了,背后靠着阿里云。星空君非常看好达摩院的大模型,之前看到达摩院在打磨面向AI算力的RISC-V“玄铁”CPU的时候,就看明白它要干什么了。或许过一段时间,江湖会有屠龙刀出现。
而华为有一项业务就很少有人知道了,它是全球前五大云计算厂商(中国排第二,仅次于阿里云)之一,市场占有率2.8%左右。

在政务云等专业云领域,华为云在多个细分市场都是国内第一。
正是依托于自身的云计算业务,华为才有了建设大模型的能力。
同样的,搞云计算的厂商,都有机会在大模型领域“大力出奇迹”。
比如默不作声的腾讯,腾讯云是国内云计算第三把交椅,搞出来个混元大模型。
据介绍,腾讯混元AI大模型目前主要覆盖NLP(自然语言处理)、CV(计算机视觉)、多模态等基础模型和众多行业/领域模型。
此外,腾讯方面表示,近期混元AI大模型团队也推出了万亿中文NLP预训练模型HunYuan-NLP-1T,实现在中文语言理解能力上的新突破,而且得益其低成本、普惠等特点,目前HunYuan-NLP-1T大模型已成功落地于腾讯广告、搜索、对话等内部产品并通过腾讯云服务外部客户。混元NLP大模型未来一方面会着力于探索更大的模型参数规模,另一方面也会结合音频、图像、视频等多模态信息,进一步打造更强大的多模态AI大模型。另外随着AIGC(人工智能内容生成)方向的火热兴起,未来混元AI大模型也会不断推进在文本内容生成、文生图等领域的持续升级。
总体来说,星空君对第四次工业革命的技术储备还是很乐观的。
我知道很多人看不起中国的高科技企业,就像当年看不起小米加步枪。
毕竟,之前的工业革命,我们连看客的资格都没有:
在英国人瓦特改良蒸汽机的时候,乾隆正在下江南;德国人本茨发明汽车的时候,中国刚刚结束两次鸦片战争;美国人莫克利和艾克特发明第一台计算机的时候,中国全面内战爆发。
而这一次,我们不会再错过了。


