

在这场AI变革中,我们或将见证更多小团队甚至个体,依靠AI技术杠杆创造出前所未有的可能性。
没有企业介绍,也没有公司水牌。若非每天晚上半层楼灯火通明,都很难知道在朝阳区的星地中心还隐藏着一家叫做水木AI的清华系AI公司。

DeepSeek爆火,让国内的AI市场一下又活跃了起来,投资人忙着托关系搞点额度。到后来,只要能和公司搭上线,也会变成投资经理年度复盘时浓墨重彩的一笔。
DeepSeek不仅大大降低了大模型原本高不可攀的训练门槛,也燃起了一级市场对于AI投资新一轮的集体热情。“其实不止我们,好几家投资机构其实在一年多以前有机会布局DeepSeek的”,一个投资人遗憾的说,“但是没办法,在24年算力为王的共识下,没人敢去布局所谓的小参数模型。”
错过了DeepSeek,投资人一方面开始追求其他量化背景的团队,清华系的九坤量化也被资本推着入局了AI战场。同时,大家也开始翻看过去两年的投资纪要,看看是否有错过的行业另类玩家,也希望能复制一个点石成金的神话。
这时,水木AI逐渐浮现出来。
1.低调的水木AI
一家低调的清华系团队,没有PR也没有融资。由清华计算机系人工智能所马少平教授作为顾问,团队在2023年底全球最早推出了混合小模型技术并完成了国内LLM算法备案。其利用多参数模型的混合和路由,实现低参数环境下的高效模型训练,在2024年就被硅谷的研究机构Leonis Capital列为未来AI领域可能出现的新范式。

最近杭州六小龙的火爆,让大家已经忘记了清华系是国内大模型根正苗红的老家,而水木AI的团队,不仅仅有智能技术与系统重点实验室马少平教授的指导,两位创始人也是根正苗红的清华连续创业者。
公司CEO陈飞是清华计算机系博士,师从马少平教授,主攻NLP方向,毕业后连续两次创业,分别在手游和AI方向。2017年,其作为CTO联合创立的AI情绪计算公司FaceThink在快速完成两轮融资后,被教育龙头好未来集团(学而思母公司)全资收购。其后,陈博士作为核心团队之一推进了好未来集团AI工程院的创建和发展,并带领团队一手打造了业内领先的好未来AI课WISROOM,是国内最早利用AI技术赋能教育的产品。
公司总裁纪晨握有美国宾夕法尼亚大学计算机和清华大学工商管理双学位,在金融界打拼十余年。职业生涯从华尔街投资银行开始,其作为7名创始团队发起的新程投资,管理规模超过30亿美金,被全球私募龙头TPG资本全资收购,纪晨也作为TPG Solutions的董事总经理,管理其中国投资业务。TPG在2021年完成IPO后,纪晨先生于同年在市场高峰激流勇退,联手老同学创立了水木AI。
清华毕业,成功连续创业者,技术结合资本,大学同学和死党。
这一系列标签已经最大化的增加了创业成功的可能性。不仅如此,陈飞将一路创业的老团队整体抬进了新公司,希望复制“老人做新事”的成功法则。而凭借沉浸香港金融圈多年的关系,纪晨也为公司拉来了顶级的天使投资人天团。前华平投资中国区主席、TPG资本的中国董事长孙强和蚂蚁金服作为最大LP的AI基金SNZ Capital为首,在团队尚未正式成立之时,就完成了数百万美金的出资。甚至天使轮的交割还未完成,机构投资者已经送来了下一轮的融资意向书。
但是很快,资本市场的寒意迅速蔓延,国内的早期投资市场几乎被冰封。
现实vs.信念:选择大模型还是小模型?
时间回拨到23年,OpenAI的横空出世,在欧美引起轰动,估值瞬间被推高到千亿美金。而在大洋彼岸的中国,虽然市场已经遇冷,但是大模型公司带来的无限想象,还是拨动着大家的神经。
春节后的北京乍暖还寒,水木AI的会议室里却是热火朝天。彼时,市场都在招兵买马。美团王慧文斥资数亿美金,高调收纳AI共创之人。陈飞的清华同实验室师兄,搜狗创始人王小川也高调下场,携过亿美金加入了这场AI这场大战役。水木AI的桌上,摆着投资人的千万美金TS,也愿意高调下注大参数模型的开发。
然而,基于多年的创业经验,团队判断基于公域数据的大模型最终会变成一个基础设施,而资本充足的运营商或互联网头部企业更有机会占据先机。对于资源有限的初创团队,通过在AI应用侧结合场景,利用颠覆式的工程能力创新,则会显著提升胜率。陈飞和马老师一样,是技术派的务实主义者,他们并不完全相信眼下的next-token prediction路径是通往AGI的最终方向,而更愿意一步步来打造顺应当下技术能力的AI应用。
纪晨从商业和融资的角度也得到了相同的结论。国情的差异决定了中国的大模型公司很难匹配美国同类公司的定价,却要背负更高的算力和落地成本。同时,他判断大模型赛道更多拼的是号召力和融资能力,产品落地和资本退出的通路却并不清晰。
商业侧,这似乎不是一个复杂的选择。但是在资本寒冬,要亲手拒绝掉投资人送来的支票,是一个很痛苦的选择。
那晚的讨论一直持续到凌晨,团队最终还是决定了以AI应用为最终落地方向,而在技术侧聚焦混合小模型作为主要的发展路径。公司的天使投资人也认可团队的专注,在第二天给团队追加了千万级的投资。
另类路径:只用16张卡的底层模型公司
在申请大模型备案的文件中,水木AI介绍了自己的混合小模型技术,强调了如何只用了2台8卡的机器,就完成了数个场景小模型的训练,且和通用大模型相比效果优异。水木AI混合模型在场景的落地方案,还从数千个团队中脱颖而出,拿下了第七届 “创响中国”全球创业大赛一等奖。
2025年春节,DeepSeek基于R1蒸馏的7B小模型,在专项能力上已经能超过OpenAI彼时最先进的GPT-4o的云端模型能力。而早在2023年底,全球还尚无相关理论支持之时,水木AI团队已经利用实现了将数个不同参数的小模型(包括0.5B-13B)经过混合和调度,实现专项场景上能力对通用大模型的超越。其原理一方面,通用大模型在专项场景上呈现出明显的算力溢出,造成了极大的能力闲置,即使MoE架构一定程度上缓解了算力浪费,但庞大的载入参数量对模型部署依然提出了苛刻的硬件要求;另一方面,通用大模型的不同能力在训练中也表现出一定的相互抑制,导致放眼全局的通用模型在专项能力上始终难以达成最优解。
水木AI的混合模型,只关注相关落地场景,提炼出所需要的AI能力并进行针对性的训练,实现比大模型性能更优异的小参数功能模型。在24年,水木AI混合模型技术落地以后,全球范围内相关的论文开始陆续问世,不仅从实验结果,也从理论层面,论证了小模型在场景落地上的领先性。
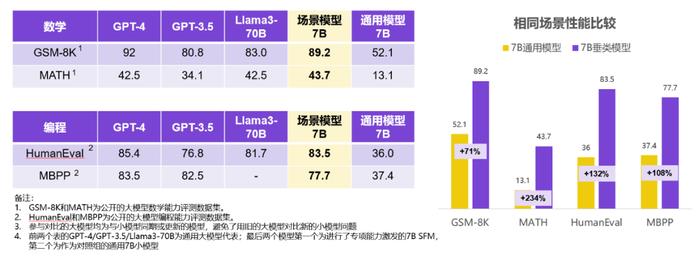
通过牺牲泛化性,将模型能力更聚焦于特定功能,不仅降低成本提升了性能,还显著优化了大模型的幻觉问题。
模型训练的本质都是基于数据分布进行收敛和对齐,而在混合小模型训练中,对专项能力的聚焦使得数据分布较为集中可控,也导致数据质量的重要性要远大于数据规模。这些数据不具有通用性,没法从市场现有的数据购买,只能自己去挖掘和产生。此时,水木AI团队过往在搜索引擎研发和数据挖掘的经验发挥了重大的作用。
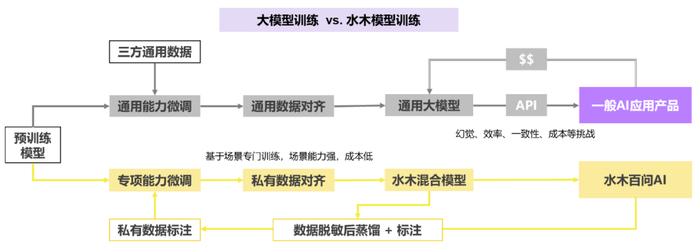
以水木AI群聊模型为例,由于群聊场景不仅仅是要预测response内容,还要同步预测response角色和topic flow,因此无法直接复用基于query-response结构的传统问答格式数据。团队创造性地利用大模型现有能力,基于精心构建的特殊prompt和数据生成工作流,来自主创造、校验和迭代群聊AI场景的高质量数据,实现小模型的能力蒸馏。随着业务持续发展,平台还能收集特定格式的数据来不断做在线学习。
商业化方面,水木AI最早盯上的赛道是AI+电商。即利用AI替代传统电商客服,进行产品的介绍和导购。不仅因为其市场规模大,也是因为水木电商混合模型较强的多模态能力,能够快速基于音视频输入直接进行端到端的模型训练和微调,省去了大量的文字翻译、校准、对齐等问题。

水木AI模型在和国内头部的大模型的对比测试中独占鳌头,在回复准确度、商品信息学习、幻觉控制、延时等各方面均具备显著的优势。同时,因为参数规模小,其后期使用成本和并发支持规模也远优于普通大模型。不仅很快就和国内两家收入破百亿的头部电商建立了合作,在海外也引起了乐天百货、新光三越等品牌的兴趣。
在电商AI的初战告捷,让团队更确定了小模型在垂类场景落地的可行性。但团队并没有停下探索其他机会的脚步。他们始终相信,最终AI应用的爆发式机会在C端。
商业化从0到1:从卖tokens到卖产品
所有做AI的人,只有卖课的挣到钱了。
虽然是个段子,也体现了24年大部分AI公司的窘境。在行业早期,商业模式不清晰,投入产出比差,加之市场的融资环境弱,大家对于新模式的探索都异常谨慎。
水木AI却从未停止自己的脚步,在一次次碰壁中也从未犹豫。在2024年下半年,AI+消费电子的突然升温,像一扇门缓缓敞开,金色的光从门缝照进来。
AI+消费电子,似乎天生就是为混合小模型定制的。
大到汽车,小到手表,现在的硬件天生都带有边缘算力。“我们相信最终AI会全面部署在各种硬件产品上,但是完全的本地化部署还需要一个过程。”陈飞博士介绍到,“但是水木AI聚焦于小参数模型以及场景驱动的快速训练,天然适合端侧场景化部署。”
成本比大模型降低80%,延时减少70%,还能优化困扰大模型的场景化性能、风格一致性、多Agent协同和幻觉等问题,是水木AI布局软硬结合的杀手锏。但是团队清楚,比技术更重要的,永远是找准市场需求和提供价值。
团队很快确定了AI for kids这个方向,利用AI为3-12岁孩子解决学习、陪伴和社交的需求。依托于过往打造好未来AI课的经验,团队对于目标群体非常了解,也具备了儿童类赛道快速产品设计和资源链快速协同的条件。
从24年3季度开始产品研发,4季度就推出了第一个产品,水木百问AI伴学机。在传统学习机课程的基础上,叠加了AI老师,AI智慧排课,AI陪练等实用功能。利用混合模型带来的成本优势,其成本较之普通平板学习机低70%以上。优质的产品,超低的价格,好未来AI课创始团队的经验沉淀,再加上清华AI的背书,让首款产品迅速出圈。
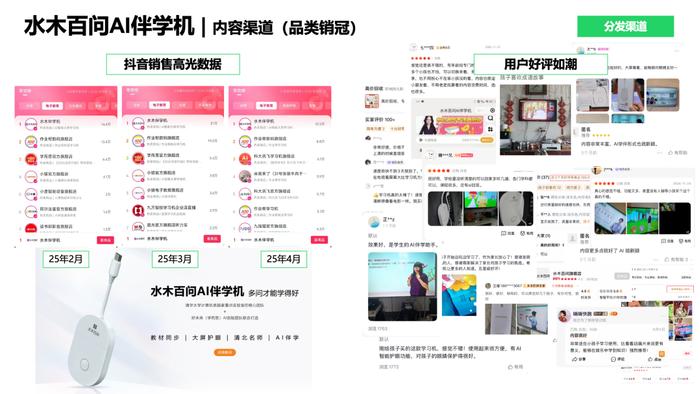
上市首月销量破万台,抖音AI伴学品类No.1,商品好评率满分。
这可能是AI时代PMF验证最快的产品之一。短短一个季度的时间,水木AI便从一个靠卖模型tokens的团队,成为了儿童AI品牌,并且打造出消费级爆款产品。通过构建销售渠道和网络,为产品矩阵提供了多元化渠道支持。
从1到10:从AI硬件产品到AI内容平台
第一批找上门来的是电子教育硬件公司。在这个传统红海市场,大家已经杀的面红耳赤,短兵相见。水木百问的突然冒出,搅乱了市场的既有格局。这个技术驱动,明星团队,口碑营销,价格低廉的“另类”产品,通过革新化的AI体验,开辟了一条差异化发展路径。这让多年习惯了靠压低成本、铺广告营销的硬件厂商坐不住了。主动上门寻求合作,希望接入水木AI的底层技术和品牌,共同构建AI+教育的新生态。
接踵而至的是玩具公司。在25年的全球消费电子展(CES)上,AI结合玩具成了最耀眼的明星。能交互,能陪伴,能成长,AI叠加硬件产生了一种中间态的新产品体验。但是当各种玩具纷纷接入了通用大模型后,才发现千篇一律的对话方式,很快让用户失去了兴趣。缺乏系统性的内容体系和规模化的内容储备,让AI玩具陷入了能玩但不好玩的困境。
真正能拉开体验差距的,并非其承载的硬件,而在于AI交互式内容本身。
团队经过对全球儿童化内容的考察和分析,发现在内容中加入游戏化元素,能显著提升内容的交互体验和用户黏性。而游戏化内容,是一个大家讨论多年,却一直受限于技术和生产成本,未能大范围铺开的内容形态。
基于水木AI伴学机上的交互内容,团队打造了一个能够快速批量化生成游戏化内容的Multi-Agent体系,替代传统游戏化内容生产的人工部分,快速在水木百问平台上构建AI生成的游戏化内容池。“体验还需要不断优化和迭代,但是生产质量和效率远远超过我们预期。”陈飞向我们透露,“因为水木百问AI生成式平台还未对外开放,核心数据也不方便披露,但是基本上具备了平台级内容生成能力和用户承载量。”
平台上的每一个游戏化内容,都支持非线性叙事和多角色参与,让孩子从被动的看内容,变成像玩RPG游戏一样的主动参与到内容中,真正做到千人千面。为了方便用户更好的体验平台的内容,水木百问也计划推出自己的第二个单品,一款孩子专属的一站式AI掌中宝。其不仅集成了水木AI为儿童专属打造的内容平台和AI陪伴功能,也结合了市场其他的AI主流应用,希望给市场上参差不齐的AI陪伴类产品树立一个标杆,继续打造水木百问的AI for Kids品牌形象。

25年春节期间,水木百问为AI伴学机的用户提供了部分内容的免费体验,反馈非常好。后续将开放平台,为国内儿童类硬件同行开放预装服务。
团队始终相信,AI发挥最大价值的地方,还是内容的批量化生成,以及沉浸式的交互体验。在水木AI的平台上,利用底层的多Agent协同体系,让用户可以0代码,0美术的生成海量AI游戏化内容,去服务全球用户群体。平台已经在终测阶段,计划在6月底公开对外测试。
平台一侧通过水木百问AI+硬件的模式,已经握有10万+精准付费用户,后续随着生态的接入将提供海量数据。另一侧,将传统内容AI化,为平台产生海量AI内容沉淀,形成正向飞轮,而水木百问正在逐渐成为孩子们最喜爱的AI品牌。
公司23年收入只有50万,24年收入超过了500万。在25年仅用了一个月,就超过了24年的销量,全年预期收入超过1个亿。
而超过70%为产研团队的水木AI,全公司人数只有不到30人。
尾声:AI时代的新创业范式
或许我们的思维还停留在互联网时代巨头数万人的体量。
在美国,Notion AI团队仅10人,在23年实现了超过3000万美元的收入。Midjourney创始团队11人,仅通过对Discord的社区运营,在23年也实现了超过1亿美元的收入。音乐生成团队Suno AI,团队不到10人,打造出月活超过50万,估值超过5亿的音乐生成软件。
在国内,水木AI也许只是一个缩影。在这场AI变革中,我们或将见证更多小团队甚至个体,依靠AI技术杠杆创造出前所未有的可能性。而我们每个人,都有幸参与到了这场技术信仰的变革中。
(封面图来源:摄图网;文中未注明图片来自水木AI)


财经自媒体联盟













































 第一财经日报
第一财经日报  每日经济新闻
每日经济新闻  贝壳财经视频
贝壳财经视频  尺度商业
尺度商业  财联社APP
财联社APP  量子位
量子位  财经网
财经网  华商韬略
华商韬略 
4000520066 欢迎批评指正
All Rights Reserved 新浪公司 版权所有
