
众所周知,随着生成式AI技术的走红,它已经开始在一些企业的业务流程里“大放异彩”。无论是用于辅助设计、还是智能客服、亦或内部的管理,这些最新的AI大模型都带来了惊人的效率提升。
但与此同时,对于AI大模型而言,其训练和推理所需的庞大算力,往往也成为了潜在用户都不得不面对的一大难题。
在这样的背景下,使用公有云IaaS(基础设施即服务)、而非自建算力基础设施,就成为了许多企业降本增效、拥抱AI大模型时代的重要举措。例如在近日公布的《2025年IDC MarketScape:全球公有云基础设施即服务(IaaS)报告》中,全球市场分析机构国际数据公司(IDC)就明确指出,随着企业将更多工作负载迁移到云端、并创建新的云原生应用,公有云IaaS继续快速增长,预计2025年IaaS的整体规模将达到1880亿美元。
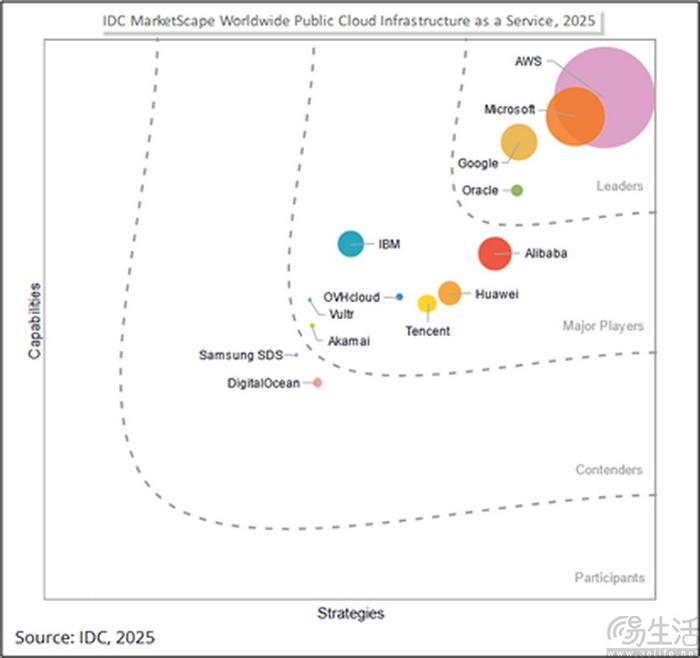
不过正如IDC报告中所阐述的那样,由于AI正在通过多种方式“重塑”云基础设施,也就意味着并非所有的IaaS服务商都已经针对AI时代的需求做好准备。在现有的IaaS行业中,无论从能力、还是战略的维度进行考量,亚马逊云科技都以显著的优势被IDC评为了行业领导者。
那么,为什么会是亚马逊云科技,在如今的IaaS行业里,他们又到底有着怎样的独特优势呢?结合IDC的这份报告以及更多的公开信息,其实并不难找到这个问题的答案。
遍布全球的可靠基础设施,是亚马逊云科技的底气
对于任何一家IaaS服务商而言,安全、稳定,且能够保证足够可用性的基础设施节点,无疑是一切的基础。而说到对于基础设施的建设,这确实也是亚马逊云科技相当突出的“底气”。

根据公开信息显示,截至目前为止,亚马逊云科技的基础设施已遍及36个地理区域的114个可用区。同时,他们已经公布了包括新西兰、沙特等在内的4个新建区域、12个可用区的建设计划。
针对数据中心本身的硬件稳定性,亚马逊云科技还进行了诸多创新设计。比如,他们成功简化了数据中心的电气和机械设计,将潜在的电气问题减少了89%,同时令基础设施可用性提高到99.9999%。而通过集成风冷与液冷功能的新设计冷却系统,亚马逊云科技不仅大幅降低了数据中心的冷却成本,促进本身算力的“降本增效”,同时还使得他们的数据中心能够支撑起用于AI的超级计算解决方案,即便在持续的超大规模压力下也长期稳定无虞。
当然,对于许多企业来说,他们的业务可能遍及多个区域,再加上大模型的训练往往也需要用到超大规模的算力集群,这就对IaaS的网络性能也提出了更高的需求。

针对这一点,亚马逊云科技一方面允许多区域之间的实时数据一致性,为大规模的跨国业务做好了网络基础设施的准备。另一方面,就在2024年的re:Invent上,亚马逊云科技还推出了第二代UltraCluster网络架构(也称为"10p10u"网络),支持超过20000个GPU协同工作,带宽达10Pb/s,延迟低于10μs。如此一来,对于需要超大规模集群训练的任务来说,仅仅这一个网络性能的跃升,便可以将训练时间缩短至少15%。再加上能在不到1秒内恢复网络的全新SIDR网络协议,令亚马逊云科技的分布式计算网络无论是效率还是可靠性,都成为了绝对的业界标杆。
当然,在先进的数据中心和网络硬件基础上,亚马逊云科技更是将“安全性”放在了系统根基的位置。无论是基础设施还是服务,它们从一开始被设计的时候就会以安全作为首要目标,并在运营过程中不断引入新技术,进一步提高安全性。举例而言,通过运用自动推理技术,亚马逊云科技为旗下关键系统的运行提供了严格的数学保证。而且值得一提的是,这些安全设计和技术,并不会因客户类型而有所差异。无论是初创企业还是大公司,它们都可以享受到同样安全的基础设施创新。
持续迭代的自研芯片,让AI算力更唾手可得
如果说遍布全球、既先进又稳定的基础设施,是亚马逊云科技能够承担起IaaS行业领导者地位的“基本因素”,那么在算力实现方式上的持续创新与领先,则可以称得上是助推亚马逊云科技能够始终领跑AI云计算时代的“长远优势”。

早在2024年3月,亚马逊云科技就与英伟达共同宣布,将结合亚马逊云科技的Nitro系统、Amazon KMS密钥管理服务、千万亿比特级的Elastic Fabric Adapter(EFA)网络和Amazon EC2 UltraCluster超大规模集群等技术,与英伟达最新的Blackwell平台和AI软件共同打造包括Project Ceiba在内的多个云端AI超级计算机系统。

需要注意的是,不同于其他的IaaS服务商,亚马逊云科技不仅能够提供基于NVIDIA GPU,以及Intel和AMD x86 CPU的常见云端算力,他们还在行业里率先对自研芯片进行了持续投入。从旨在提升网络与存储能力的Nitro系统,自研处理器Graviton、到机器学习训练芯片Trainium和推理芯片Inferentia。截至目前,所有的这些亚马逊云科技自研芯片都经过了多次迭代,并且每次更新均能提供两位数以上百分比的性价比提升。
其中以Trainium2为例,这是亚马逊云科技在re:Invent 2024期间刚推出的最新款自研训练芯片。在使用该芯片的Amazon EC2 Trn2实例中,16颗Trainium2就可提供高达20.8 Petaflops浮点算力的性能,同时性价比比基于GPU的实例提高了30-40%,非常适合训练和推理数十亿参数的AI大模型。

不仅如此,由于是自研芯片,也就意味着亚马逊云科技可以根据业务需求,对Trainium2的集群进行更大规模的扩展。在Amazon EC2 Trn2 UltraServers服务器里,它使用64块Trainium2进行互联,可提供高达83.2 Petaflops浮点算力。而且亚马逊云科技方面还在打造名为Project Rainier的EC2 UltraCluster超级计算机,其中包含数十万颗Trainium2 芯片,足可达到相当于最新、最领先的AI大模型所需训练算力的5倍以上水准。

这还没完,就在2024年年底,亚马逊云科技还官宣了下一代的AI训练芯片Trainium3。作为他们的第一款3nm制程自研芯片,Trainium3预计将在UltraServers服务器中提供相当于前代4倍的性能。最为重要的是,预计今年年内,我们就会看到亚马逊云科技的新一代推理芯片正式上线,不出意外,他们必将再次重新定义云端AI训练的“性价比新高”。
虽然已成“领导者”,但亚马逊云科技仍在进行自我革命
从各方面的公开信息来看,全球覆盖的高可靠性基础设施,以及以自研芯片为代表的硬件持续创新,可以说很好地代表了亚马逊云科技如今在IaaS业内“基础能力”与“长期战略”两个方面的突出竞争力。

正如IDC分析师、报告作者Dave McCarthy所说的那样,“亚马逊云科技通过广泛的服务组合和持续的创新,在公有云IaaS市场中处于领导地位。广泛的全球基础设施,结合Amazon Graviton等定制芯片计划以及在AI领域的重大投资,使其在满足企业需求方面独具优势。其在可扩展性方面的卓越表现、成熟的开发者社区以及对AI基础设施的积极投入,使其成为需要先进云能力的企业的首选。”
但即便如此,亚马逊云科技也还没有停止继续领跑的脚步。就在今年2月的财报电话会议上,亚马逊首席执行官Andy Jassy确认,他们在2025年的资本投资预计达1000亿美元,其中大部分将用于亚马逊云科技AI基础设施的建设。

当然,对于全球渴望“上云”体验最尖端生成式AI技术的企业来说,这绝对是一件好事。因为这不仅意味着亚马逊云科技本身还将继续提高旗下AI基础设施的能力与性价比,同时这种由亚马逊云科技“带头”的IaaS AI算力竞争,也有望促进整个行业的持续良性发展。


财经自媒体联盟












































 第一财经日报
第一财经日报  每日经济新闻
每日经济新闻  贝壳财经视频
贝壳财经视频  尺度商业
尺度商业  财联社APP
财联社APP  量子位
量子位  财经网
财经网  华商韬略
华商韬略 
4000520066 欢迎批评指正
All Rights Reserved 新浪公司 版权所有
