



日前,阿里云方面正式发布新一代端到端多模态旗舰模型Qwen2.5-Omni-7B。据了解,这也是通义系列模型中首个端到端全模态大模型,可同时、无缝处理文本、图像、音频和视频等多种输入形式,并通过实时流式响应同时生成文本与自然语音合成输出。
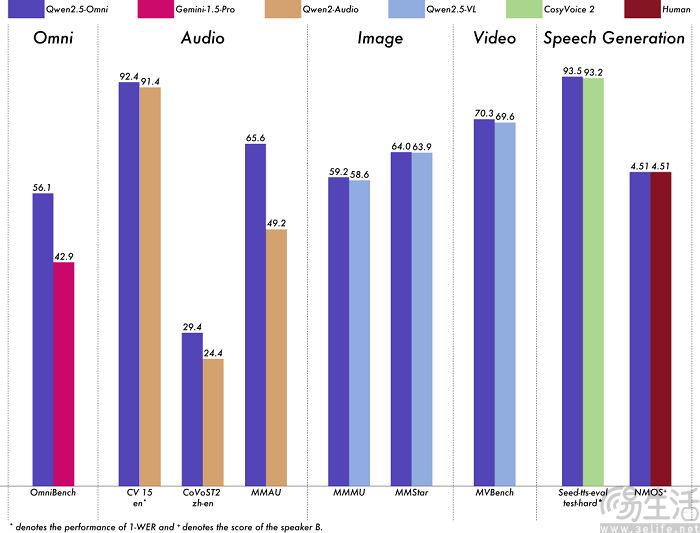
根据阿里云方面公布的相关信息显示,Qwen2.5-Omni-7B在一系列同等规模的单模态模型基准测试中,展现出全球最强的全模态优异性能,其在语音理解、图片理解、视频理解、语音生成等领域的测评分数,均领先于专门的Audio或VL模型,并且其语音生成测评分数达4.51、与人类能力持平。
而且在多模态融合任务OmniBench等测评中,Qwen2.5-Omni-7B也刷新了业界纪录,全维度远超谷歌Gemini-1.5-Pro等同类模型。
据了解,Qwen2.5-Omni-7B之所以能实现高性能,在于其采取了一系列突破性创新技术,包括阿里云通义团队首创的Thinker-Talker双核架构,以及Position Embedding (位置嵌入)融合音视频技术、位置编码算法TMRoPE(Time-aligned Multimodal RoPE)等。其中,Thinker-Talker双核架构让Qwen2.5-Omni-7B拥有了人类的“大脑”和“发声器”,形成端到端的统一模型架构,实现了实时语义理解与语音生成的高效协同。
目前,Qwen2.5-Omni-7B已在Hugging Face、ModelScope、DashScope和GitHub上开源,支持开发者和企业免费下载商用。此外值得一提的是,该模型可在手机等智能终端硬件部署、运行。对此阿里云方面表示,相较于动辄数千亿参数的闭源大模型,Qwen2.5-Omni以7B的小尺寸让全模态大模型在产业上的广泛应用成为可能。
公开资料显示,自2023年以来,阿里云通义团队已陆续开发覆盖0.5B、1.5B、3B、7B、14B、32B、72B、110B等参数的200多款“全尺寸”大模型,囊括文本生成模型、视觉理解/生成模型、语音理解/生成模型、文生图及视频模型等。
【本文图片来自网络】



