

整理 | 傅宇琪
3 月 11 日,零一万物宣布,其基于全导航图技术打造的新型向量数据库“笛卡尔(Descartes)”已成功研发,并包揽权威榜单 ANN-Benchmarks 的 6 项数据集评测第一名。
零一万物表示,笛卡尔向量数据库将应用于公司即将正式发布的 AI 产品中,未来还将结合工具提供给广大开发者。
笛卡尔霸榜,
包揽权威榜单评测六项第一
ANN-Benchmarks 是当下业界最权威的向量数据库性能测试工具,它可以展示不同算法在不同真实数据集下的表现。零一万物笛卡尔向量数据库在 ANN-Benchmarks 六项数据集测试均位居第一。(具体结果可见下图)
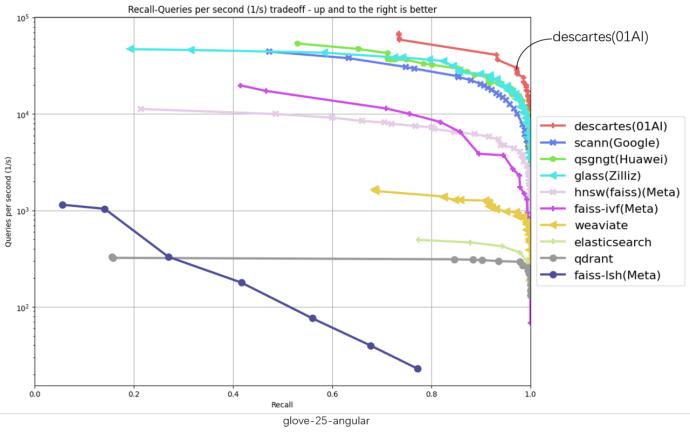


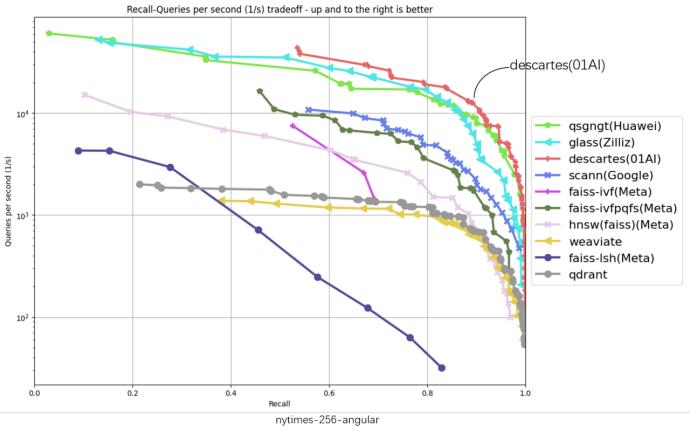


在上述六份评测结果图中,横坐标代表召回、纵坐标代表 QPS(每秒内处理的请求数),曲线位置越偏右上角意味着算法性能越好。可以观察到,代表笛卡尔的红线在六张图中都处于最高位。

在原榜单 TOP1 基础上,零一万物笛卡尔向量数据库实现了显著性能提升,部分数据集上的性能提升超过 2 倍以上,在 gist-960-euclidean 数据集维度更大幅领先榜单原 TOP1 286%。
解决检索难题的“杀手锏”
向量数据库,又被称为 AI 时代的信息检索技术,是检索增强生成(Retrieval-Augmented Generation, RAG)内核技术之一。向量数据库专门用于存储、索引和查询由非结构化数据(如文本、图像或音频)生成的嵌入向量。这些嵌入向量是通过将非结构化数据转换为高维向量来创建的,以便于快速查找和检索类似对象。与传统的关系数据库不同,向量数据库主要面向非结构化数据,并采用相似度索引来返回查询结果,而不是基于关键字的查找。
向量数据库的核心能力包括低成本存储和高性能计算,具体功能包括用于搜索和检索的向量索引、单级过滤、数据分片、复制、混合存储以及 API 等。随着非结构化数据应用的增加,向量数据库在处理分析这类数据方面的需求也在增长。其主要应用领域包括人脸识别、推荐系统、图片搜索、视频指纹、语音处理、自然语言处理、文件搜索等。
对大模型应用开发者来说,向量数据库是非常重要的基础设施,能够影响大模型的性能表现。大模型虽然强大,但存在实时信息更新慢、隐私保护问题、推理失真以及推理效率低等缺陷。向量数据库通过其轻量化更新机制、隐私保护特性、丰富知识参照以及作为缓存机制的功能,能够精准地解决大模型的这些痛点。
零一万物表示,笛卡尔向量数据库在处理复杂查询、提高检索效率以及优化数据存储方面相比业界拥有显著的比较优势,它主要能用于解决两大类问题。
通过建立某种索引结构,减少检索考察的候选集
目前业内现状主要通过哈希、KD-Tree、VP-Tree 等方式,导航效果不够精确,裁剪力度不够,零一万物研发的全局多层缩略图导航技术,图上坐标系导航,既能保证精度,又能裁剪大量无关向量。
零一万物还首创了自适应邻居选择策略,填补业界空白。零一万物自研的自适应邻居选择策略,突破了以往仅依赖真实 topk 或固定边选择策略的局限,新策略使每个节点可以根据自身及邻居的分布特征动态地选取最佳邻居边,更快收敛接近目标向量,从而让 RAG 向量检索性能提高 15%-30%。
降低单个向量计算的复杂度
零一万物采用了两级量化方案增强 RAG。零一万物用两级量化降低计算复杂度,同时列式存储充分利用 SIMD 的并发能力,进一步发挥硬件能力,相比传统 PQ 查表,性能得到大幅提升到 2-3 倍。
除此之外,零一万物还有索引结构优化、连通性保障等全栈向量技术方案提高笛卡尔向量数据库的性能。
零一万物笛卡尔向量数据库目前聚焦于高性能向量数据库,通常指向量数据集规模在千万级及以下(如 2000 万 128 维浮点型向量),在实际应用场景中,具有超高精度、超高性能等核心优势。
高性能向量数据库可以轻松应对 80% 以上的日常场景,如构建私域知识库、智能客服系统,加速自动驾驶模型训练……以医疗影像诊断为例,随着医学影像技术的不断发展,大量的医疗影像数据需要被存储、检索和分析。这些影像数据可以通过特征提取转化为向量表示,进而利用高性能向量数据库进行高效检索和匹配。医生在诊断过程中,可以利用向量数据库快速检索与当前病例相似的历史病例和影像资料,从而辅助医生做出更准确的诊断。
零一万物表示,笛卡尔向量数据库是团队基于 RAG 的初步尝试,将在近期发布的 AI 生产力产品中得到有效应用。


