

整理 | 凌敏、核子可乐
世界最强开源大模型又双叒叕易主了!
Databricks 推出开源大模型 DBRX
3 月 27 日,美国 AI 初创公司 Databricks 宣布,该公司 Mosaic Research 团队开发的通用大模型 DBRX 将开源。Databricks 客户可以通过 API 使用 DBRX,从零开始预训练自己的 DBRX 同类模型,或者使用其构建该模型的同款工具和技术在选定的检查点之上继续训练。
据悉,DBRX 的设计灵感来源于 OpenAI 的 ChatGPT。Databricks 表示,它花费了大约 1000 万美元和三个月的时间来训练 DBRX,并声称其“在标准基准上优于所有现有的开源模型”。Databricks 的首席神经网络架构师兼 DBRX 项目负责人 Jonathan Frankle 在确认了测试结果后向团队宣布:“我们已经超越了所有现有模型”。
量化测试结果显示,DBRX 性能已经超越 GPT-3.5,且完全能够与 Gemini 1.0 Pro 相比肩。其推理速度比达到 LlaMa2-70B 的 2 倍;而就总参数量和活动参数量而言,DBRX 的大小约为 Grok-1 的 40%。在被托管于 Mosaic AI Model Serving 上时,DBRX 能够以高达 150 tokens/ 秒 / 用户的速度生成文本。同时,DBRX 也是一套极其强大的编码模型,在编程方面甚至超越了 CodeLlaMa-70B 等专业模型。
在最终模型质量相同的情况下,训练混合专家的 FLOP 效率约为训练密集模型的 2 倍。从端到端角度出发,DBRX 整体配方(包括预训练数据、模型架构和优化策略)完全能够与上一代 MPT 模型提供同等输出质量,但计算量却减少至约四分之一。

DBRX在语言理解(MMLU)、编程(HumanEval)和数学(GSM8K)方面优于原有开源模型。
DBRX 是如何构建出来的?
DBRX 是一套基于 Transformer 的纯解码器大语言模型(LLM),使用下一 token 预测方式进行训练。它使用细粒度的混合专家(MoE)架构,共有 132B 参数,其中 36B 参数在任何输入上均处于活动状态。DBRX 的预训练使用到 12 T 大小的文本与代码数据 tokens。
与 Mixtral 和 Grok-1 等其他开放混合专家模型相比,DBRX 具有细粒度特性,意味着它使用到数量更多的小型专家模型。DBRX 共含 16 个专家模型,在推理中选取输出质量最高的 4 个;而 Mixtral 和 Grok-1 则包含 8 个专家模型,每次推理时选择其中 2 个。这意味着 DBRX 的潜在专家组合相当于同类开放模型的 65 倍,这也在实践中切实提高了模型质量。DBRX 使用旋转位置编码(RoPE)、门控线性单元(GLU)和分组查询注意(GQA)机制,还用到了 tiktoken repo 中提供的 GPT-4 token 生成器。
DBRX 在精心设计的 12T token 数据与 32k 最大上下文长度条件下进行了预训练。Databricks 估计这样的配置数据在训练质量上至少达到此前 MPT 系列模型预训练数据的 2 倍。这套新数据集使用全套 Databricks 工具开发而成,包括用于数据处理的 Apache Spark 和 Databricks notebooks,用于数据管理与治理的 Unity Catalog,以及用于实验跟踪的 MLflow。Databricks 还使用课程学习进行预训练,在训练期间改变数据组合,并发现这样能够显著提高模型质量。
据介绍,DBRX 在通过 3.2 Tbps InfiniBand 实现互连的 3072 张英伟达 H100 上训练而成。构建 DBRX 的主要步骤包括:预训练、后训练、评估、红队测试和精炼,全程历时三个月。除此之外,Databricks 还持续开展长达几个月的数学、数据集研究与扩展实验。
为了构建 DBRX,Databricks 打造出一款未来客户也能用到的工具,使用 Unity Catalog 对训练数据进行管理与治理,同时采取收购而来的 Lilac AI 资产探索这些数据,并使用 Apache Spark 和 Databricks notebooks 清洗并处理这些数据。
Databricks 使用开源训练库的优化版本来训练 DBRX,包括 MegaBlocks、LLM Foundry、Composer 和 Streaming。使用 Mosaic AI 训练服务在数千个 GPU 上管理大规模模型训练与微调任务。使用 MLflow 记录结果,并通过 Mosaic AI 模型服务与推理表收集到大量来自测试人员的质量和安全改进反馈。使用 Databricks Playground 手动测试了这套模型,并发现其打造的工具在各种用途上均有领先表现,完全能够带来和谐统一的产品体验。
目前,DBRX 已经被整合至 Databricks 的生成式 AI 支持产品当中,包括 SQL 等应用,且早期表现已经超过了 GPT-3.5 Turbo,足以向 GPT-4 Trubo 发起冲击。DBRX 在 RAG 任务上同样力压 GPT-3.5 Turbo 以及其他各种开放模型。
训练效率与推理效率
模型质量无法孤立存在,必然要与模型训练和使用效率联系起来。Databricks 发现,训练混合专家模型能够显著提高训练过程的计算效率(详见下图。例如,在训练名为 DBRX MoE-B(总参数 23.5B,活动参数 6.6B)这个较小版本时,在 Databricks LLM Gauntlet 上获得 45.5% 分数所需的 FLOP 次数仅为 LlaMA2-13B 训练工作量的 1/1.7,且后者得分仅为 43.8%。DBRX MoE-B 的活动参数也仅为 LlaMA2-13B 的一半。

从整体上看,Databricks 的端到端大模型预训练管线的计算效率在过去十个月间提高了近 4 倍。2023 年 5 月 5 日,Databricks 正式发布了 MPT-7B,这是一套在 1T tokens 上训练得到的 7B 参数模型,在 Databricks LLM Gauntlet 测试中得分为 30.9%。DBRX 家族的另一位成员名为 DBRX MoE-A(总参数 7.7B,活动参数 2.2B),其 Databricks LLM Gauntlet 测试得分为 30.5%,但训练 FLOP 量减少至 1/3.7。这样的效率提升源自一系列改进举措,包括使用混合专家架构、对其他网络架构的调整、更好的优化策略、更好的令牌化方法,以及更高的预训练数据质量等等。
单独来看,预训练数据的优化对模型质量产生了重大影响。Databricks 使用 DBRX 预训练数据在 1T tokens 上训练得出一套 7B 模型(名为 DBRX Dense-A)。其在 Databricks LLM Gauntlet 测试中的得分为 39.0%,远高于 MPT-7B 的 30.9%。Databricks 估计,新的预训练数据在质量方面至少相当于 MPT-7B 训练数据的 2 倍。换句话说,要达到相同的模型质量,现在只需要使用一半 tokens。Databricks 还在 500B tokens 上训练了 DBRX Dense-A 来验证这一猜测,发现它在 Databricks LLM Gauntlet 上的表现同样优于 MPT-7B,得分为 32.1%。除了更高的数据质量外,提升训练效率的另一大重要因素很可能是 GPT-4 令牌化器。其中包含大量词汇,而且被普遍认为具有极高的令牌化效率。
推理效率和模型质量之间往往相互冲突:较大的模型往往拥有更高的输出质量,但较小的模型往往推理效率更高。使用混合专家架构则能够在模型质量与推理效率之间实现超越大部分密集模型的权衡效果。例如,DBRX 的质量比 LlaMA2-70B 更高,而且由于活动参数量仅为 LlaMA2-70B 的一半左右,所以 DBRX 推理吞吐量最高可达其 2 倍(参见下图)。Mixtral 则是混合专家模型实现帕累托式改进的另一明证:它的体量比 DBRX 更小,质量也相应较低,但推理吞吐量则更高。Databricks 基础模型 API 的用户预计可在经过优化的 8 位精度模型服务平台上,获得每秒最高 150 toknes 的 DBRX 推理性能。
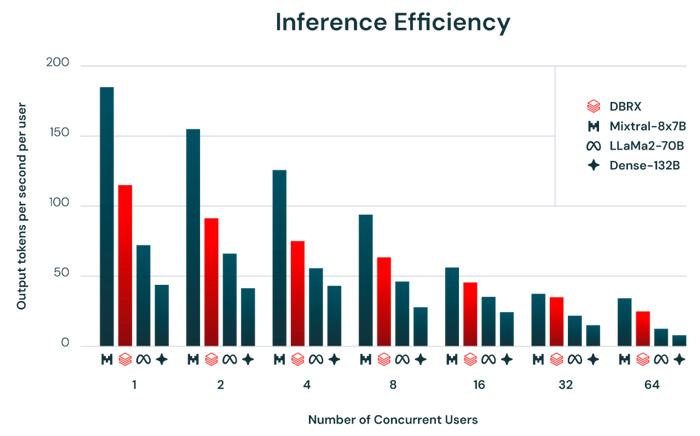
使用英伟达 TensorRT-LLM,在 Databricks 经过优化的服务基础设施上以 16 位精度实现的各种模型配置推理吞吐量。模型在整个节点上以张量并行方式运行。输入提示词包含约 2000 个 tokens,生成的输出则包含 256 个 tokens。每秒新增一个用户。
与其他领先大模型的基准测试比较
在与其他领先的开放模型的基准测试比较结果中,DBRX Instruct 在综合、编程和数学基准以及 MMLU 等方面均表现出色,在标准基准测试中甚至成功超越了所有话语或指令微调模型。
Databricks 根据两项综合基准评估了 DBRX Instruct 与其他同类开放模型的差异,具体包括 Hugging Face Open LLM Leaderboard(即 ARC-Challenge、HellaSwag、MMLU、TruthfulQA、WinoGrande 和 GSM8k 的平均值)以及 Databricks Model Gauntlet(涵盖 6 大领域超 30 项任务的套件,具体包括世界知识、常识推理、语言理解、阅读理解、符号问题解决和编程)。
在参与评估的模型中,DBRX Instruct 在两项综合基准上得分最高:Hugging Face Open LLM Leaderboard(得分 74.5%,高于第二位 Mixtral Instruct 的 72.7%)和 Databricks Gauntlet(66.8%,高于第二位 Mixtral Instruct 的 60.7%)。
DBRX Instruct 在编程和数学方面尤其擅长。其得分高于 Databricks 在 HumanEval 上评估的其他开放模型(得分为 70.1%,高于 Grok-1 的 63.2%,Mixtral Instruct 的 54.8%,以及 LlaMa2-70B 性能最高变体的 32.2%),GSM8k 测试同理(得分为 66.9%,高于 Grok-1 的 62.9%,Mixtral Instruct 的 61.1%,以及 LlaMA2-70B 性能最高变体的 54.1%)。DBRX 性能全面优于在基准测试中表现第二好的 Grok-1,且后者的参数量达到 DBRX 的 2.4 倍。在 HumanEval 测试中,DBRX Instruct 甚至超越了专为编程而构建的模型 CodeLlaMA-70B Instruct,而前者只是针对通用用途而设计(得分为 70.1%,高于 META 在博文中公布的 67.8% HumanEval 得分)。
此外,DBRX Instruct 的得分高于 Databricks 在 MMLU 测试上测量的所有其他模型,达到 73.7%。
在与其他领先的封闭模型的基准测试比较结果中,DBRX Instruct 几乎全部超越 GPT-3.5,且最差得分也与 GPT-3.5 相当。DBRX Instruct 在通过 MMLU 衡量的常识知识(73.7% 对 70.0%)以及由 HellaSwag(89.0% 对 85.5%)和 WinoGrande(81.8% 对 81.6%)衡量的常识推理方面,均优于 GPT-3.5。而从 HumanEval(70.1% 对 48.1%)和 GSM8k(72.8% 对 47.1%)的得分来看,DBRX Instruct 尤其擅长编程和数据推导。
DBRX Instruct 的成绩几乎与 Gemini 1.0 Pro 和 Mistral Medium 相当。DBRX Instruct 在 Inflection Corrected MTBench、MMLU、HellaSwag 和 HumanEval 上的得分高于 Gemini 1.0 Pro,而 Gemini 1.0 Pro 在 GSM8k 上的得分更强。DBRX Instruct 与 Mistral Medium 在 HellaSwag 测试中得分相似,后者在 Winogrande 和 MMLU 上更强,而 DBRX Instruct 在 HumanEval、GSM8k 和 Inflection Corrected MTBench 上更强。
GPT-5、GPT-6 们即将
向最强大模型发出挑战
当前,大模型训练已经进入到了白热化阶段,最强开源大模型称号几经易主,暂时落在了 DBRX 头上。开源大模型在卷,封闭大模型也在卷。近日有消息显示,OpenAI 准备在未来几个月内发布更加强大的 AI 模型 GPT-5。与此同时,近日一条关于 GPT-6 的消息被传的沸沸扬扬。
GPT-5 方面,据《商业内幕》从两位知情人士处得到的消息,GPT-5 计划在今年夏季推出。从报道来看,发布之前已经有部分企业测试过该工具的演示版本,初步掌握了其升级功能。在之前的 GPT-4 上,AI 聊天机器人已经能够提供与人类相似的响应能力,甚至可以识别并生成图像和语音。据报道,其继任者 GPT-5 将带来更强的个性化表现、更少的错误并处理更多内容类型,最终将可支持视频。
今年二月,Altman 在迪拜举行的世界政府峰会上谈到了 GPT-5。他表示 ChatGPT 的这个最新版本将拥有超越前代的智能水平。Altman 解释称,“其中的意义将超越话语描述,因为这些模型之所以如此神奇,就在于它们有着强大的通用能力。所以只要它们能更聪明一点,那在所有用例上也都将更进一步。”Altman 在接受《金融时报》采访时强调,GPT-5 需要更多数据进行训练,这也暗示其智能水平的提升。他表示,项目计划使用互联网上的公开数据集以及来自各组织的大规模专有数据集进行训练。后者将包含各种格式的长篇文章或对话记录。
最新报道指出,OpenAI 公司已经开始训练 GPT-5,积极为今年年中的 AI 模型发布进行准备。据《商业内幕》报道,一旦训练完成,该系统还须经历多个阶段的安全测试。作为过程中的一部分,该机器人还须经历“红队测试”,即同时由内部和外部人员通过测试就其优点和短板给出反馈。
早在去年秋季至少两个不同场合上,OpenAI 掌门人 Sam Altman 就曾,亲自证明公司正在开发 GPT-5。据两位与会人士透露,第一次是在去年 9 月他曾供职的风险投资公司 Y Combinator 的员工聚会演讲当中。当时 Altman 明确表示,GPT-5 及其继任者 GPT-6 已经“只是时间问题”,而且都比前代版本更加强大。

去年 11 月,Altman 又公开承认了 GPT-5 的存在。他在接受英国《金融时报》采访时称 OpenAI 正在开发 GPT-5,但没有透露具体发布日期。
最近,一篇报道称这位 OpenAI 掌门人又提出了一项大胆的计划,决定采购训练大规模 AI 模型所需要的海量 GPU 设备。据《华尔街日报》报道,为了克服阻碍技术创新的 GPU 供应短缺问题,Altman 希望全球投资者、政府和电网机构能够帮助其筹集最高 7 万亿美元资金,借此扩大芯片制造产能。
与此同时,有关 GPT-6 的消息也在近日被广为报道。

3 月 26 日,AI 初创公司 OpenPipe 联合创始人、CEO Kyle Corbitt 在 X 上透露,自己最近与一位负责 GPT-6 训练集群项目的微软工程师谈过,后者抱怨称,在跨区域 GPU 之间部署 infiniband 级别链接,实在是一件痛苦的事。Corbitt 问到为何不将训练集群集中在同一区域,这位微软工程师回答,“我们已经尝试过那么做了,但是如果在一个州放置超过 10 万片 H100 GPU,电网就会崩溃。”

此外,一张 OpenAI 内部时间线的图片也在近日疯传。图中显示,OpenAI 早在 2022 年 8 月 -10 月就开始了 GPT-5 的训练,在去年 9 月开始了 GPT-6 的测试。虽然 OpenAI 没有给出明确的发布日期,但结合各类爆料来看,GPT-5、GPT-6 已经在路上了,即将向最强大模型发起冲击。
参考链接:
https://www.databricks.com/blog/introducing-dbrx-new-state-art-open-llm
https://www.standard.co.uk/news/tech/chatgpt-5-release-date-details-openai-chatbot-b1130369.html


