
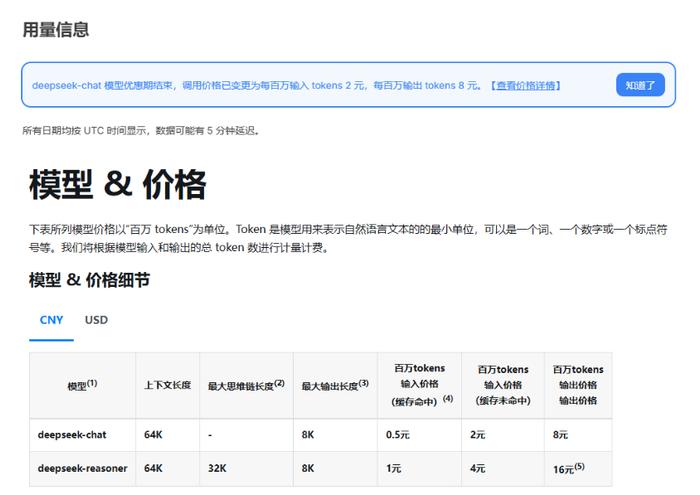
目前DeepSeek-V3 API服务的优惠价格体验期已结束,从2月9日起实施新的价格:
每百万输入Tokens 0.5元(缓存命中)/2元(缓存未命中),每百万输出tokens 8元,是体验期的4倍。
其实,这种策略并不罕见,很多AI公司都会先通过低价策略吸引用户,然后再恢复或上调价格。
DeepSeek优惠期吸引了一大批开发者,现在价格回归合理水平,也算是意料之中。
这次价格上涨的是DeepSeek-V3,不少小伙伴不清楚DeepSeek-V3和DeepSeek-R1有什么区别,今天我们就来一探究竟!
01
推理能力
DeepSeek-V3
主要是大语言模型(LLM),可以处理各种日常任务,比如文本生成、翻译、代码补全等。
它的核心机制是Mixture-of-Experts(MoE),简单理解就是“专家分工合作”,从不同的子模型中选择最合适的来完成任务。
这个模型类似于GPT-4o,适合大多数需要自然语言处理的任务。
DeepSeek-R1
主打复杂推理,专门用于解决需要深度分析的问题,尤其适用于编码挑战、数学问题、逻辑推理等。
它采用强化学习,通过“让AI自己思考并优化推理路径”的方式提升能力。
💡 通俗点讲,V3是个“通才”,啥都会一点,适合日常对话和通用任务;R1则是“学霸”,特别擅长复杂逻辑和高难度推理。
02
速度和效率
DeepSeek-V3
得益于MoE架构,响应速度很快,适合实时交互。
DeepSeek-R1
需要“思考”一会儿后才输出答案,所以速度比V3慢很多。
💡 换句话说,V3是“秒回型”,R1是“沉思型”。如果你急着要答案,V3更合适;如果你想要一个经过深思熟虑的答案,那R1值得等待。
03
适用场景
DeepSeek-V3
适合文章写作、代码补全、日常问答等。
DeepSeek-R1
适合复杂推理、算法挑战、数学证明等。
💡 举个例子,如果你要找个AI写篇文章,V3就够用了;但如果你在刷LeetCode高难度题,R1可能更靠谱。
价格上调后,DeepSeek的API性价比确实下降了,尤其是对预算有限的小团队来说,这可能是个压力。
不过,即使涨价,DeepSeek-V3的价格依然比GPT-4o便宜不少。从整体来看,它依然是市场上较具竞争力的选择。
DeepSeek的涨价虽然让部分用户不爽,但本质上也是行业发展的正常现象。对于开发者来说,选择最适合自己需求的模型,才是最重要的!
你怎么看DeepSeek的这次涨价?欢迎留言聊聊!


财经自媒体联盟













































 第一财经日报
第一财经日报  每日经济新闻
每日经济新闻  贝壳财经视频
贝壳财经视频  尺度商业
尺度商业  财联社APP
财联社APP  量子位
量子位  财经网
财经网  华商韬略
华商韬略 
4000520066 欢迎批评指正
All Rights Reserved 新浪公司 版权所有
