
作者 | 黄珊
来源 | 数据实战派
比特币
外挖无穷洞,机神犹未休。
卡中窥币影,池里验沙流。
屡载吸金主,孤深渍盗求。
方知区块链,本是古来游。
这首诗歌来自一支清华团队开发的古诗 AI。它的创作才华可不仅限于此。再看下面这首诗:
夜过虹桥机场
卢浦斜晖里,西楼醉客行。
影侵双塔晚,灯落一城明。
空客还频顾,航灯未可惊。
空留城市夜,月映水帘星。
你仍可以在文采上对它有所挑剔,但不得不承认的是,这至少是一个不会离题万里的 AI,尤其还是颇具难度的古诗生成。在这一点,它已经超越此前的作诗 AI。
论文名:Controllable Generation from Pretrained Language Models via Inverse Prompting(https://arxiv.org/pdf/2103.10685.pdf)
github:https://github.com/THUDM/InversePrompting
1
现有预训练模型的通病:文章本天成,“可控” 偶得之?
人类的诗歌创作活动是否有规律可循,还是完全由灵感支配?有一派理论认为,“文章本天成,妙手偶得之”。即好的诗歌、好的文学创作好的文章本是天生而成,只是人灵感所至偶然所得罢。当然,很多情况下所谓灵感,也要那些文学素养高,有深厚的文学基础的人才能抓得住。
对于 NLP 算法来说,它们还远远未到达这个境界。如上文所言,仅仅是不要搞 “离题创作”,就已经十分艰难。
在自然语言处理领域,作诗这一任务被归类为生成任务。目前,解决生成任务的 “当红炸子鸡” 非属预训练模型不可。
即便如此,此前的大部分预训练模型在生成符合题意的句子上仍力不从心。
这支清华团队同样经历过这种坎坷。有一次,他们从知乎摘了一个问题去提问模型 —— 说什么瞬间让你想留住这一刻?模型最终生成的句子非常通顺,但是,如你所见,这些句子并未真正回答这个问题,也就是说,这个问题和答案关联性非常弱。
我和男朋友在一起两年。我去国外留学,他留在国内。一人在国外,寂寞心酸都是真的。念书的时候,觉得常在一起没什么,两个人一起努力,吵吵闹闹就过来了。我一直这样想,以至于到了高中,到了最后几个月,我都觉得他就是我行走的小弟。其实最快乐的时候,就是一起在外头的 “孤儿院” 里。
这是一个普遍存在于预训练语言模型中的现象。
符合题意、答为所问的能力,正决定了一个 NLP 算法能不能产生现实应用价值。因为你一定不想和一个 AI 进行一段鸡同鸭讲的对话。
为了解决这个问题,团队成员提出了一个全新的文本可控生成方法 Inverse Prompting,显著提升了对预训练语言模型生成结果的控制能力,使得生成内容的质量大幅超越了一些传统方法,在问答和诗歌等生成任务中接近人类水平,并首次实现根据现代题材创作古体诗。
通过这个方法优化以后,上面这个问题的回答有了立竿见影的改变:
一瞬间想到高二的时候,那天下午在操场晒了一中午太阳,和同学一起在楼下打球,下午的夕阳徐徐洒下来,我们三个人一起站在走廊上,倚着栏杆可以面对着夕阳。一直想留下那一瞬间,可惜我以后再也没有遇到过那样的时光。
Inverse Prompting 可以让回答和问题关联性更强,即更好地利用 Prompt 的信息来控制所生成的内容。举个简单的例子,如果我们想知道如何在考试中取得好成绩,我们可以将 “问题:如何在考试中取得好成绩?答案:” 输入给模型,让模型去预测后面的语句,这里输入文本就称作 Prompt (提示文本)。
这时,模型可能会给出 “认真复习很重要。”、“上课仔细做笔记。” 这样的答案。为了评估这些答案的质量,Inverse Prompting 将这些答案反向输入给模型,让模型去预测问题的出现概率。比如将 “‘认真复习很重要。’回答了问题” 输入给模型让它计算‘如何在考试中取得好成绩?’的出现概率。
Inverse Prompting 使用原始语言模型本身生成的内容来进行改善,使得原先预训练模型在不需要进行参数精调的情况下就可以评估生成文本和 Prompt 之间的关联性(Likelihood),进而提供了更好的可控性。
最终,团队将 Inverse Prompting 应用在了多种预训练模型上(包括拥有 30 亿参数的大规模中文预训练语言模型),实现了在多种生成任务(诗歌、问答)上对于基线模型算法的大幅超越,并在图灵测试中达到了接近人类的表现。
比如,在长篇问答任务(类似于 Quora 或知乎的问题回答)中, Inverse Prompting 方法在各个方面都比 Prompting 方法和此前最先进的汉语预训练模型 CPM 模型得分高得多。除此以外,Inverse Prompting 方法可以大展拳脚的生成任务还包括宋词的生成甚至图像的生成任务上。
Inverse Prompting 虽然可以用来计算 Prompt 与生成内容的关联性,然而它依然依赖于从大量的生成内容中挑选高质量结果,比如为了生成一首质量不错的诗歌,可能需要预先生成上千首诗歌,这意味着使用预训练模型进行大量的计算。
2
Inverse Prompting + self-training,AI 写诗上 “双保险”
中国古典诗歌生成是特定领域长文本生成任务中的 “明珠”,它与现代汉语有着非常不同的表现形式和修辞用法。即便对于最先进的人工智能模型来说,生成有意义的中国古典诗都是非常困难的。
在各种超大规模的预训练文本语料中,诗词都只占其中非常小的一部分。因此,直接使用预训练语言模型对输入的 Prompt 进行计算,只有较小概率能够产生诗词类的输出。
为了提高模型输出中国诗歌概率,团队找到的解决方案是:在生成诗词语句的过程中,放松对于 Perplexity 得分的要求,增加 Beam Search 中的随机性,然后采用诗词规则及 Inverse Prompting 控制生成语句的格式及质量,使其满足中国古典诗歌的格律规范。
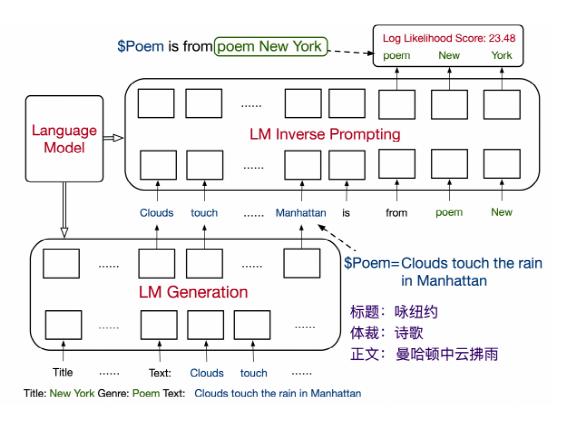 Inverse Prompting 原理示意图
Inverse Prompting 原理示意图传统的作诗模型大多基于古诗词进行模型的训练,因此它们虽然能够像真实的古代诗人一样作唐诗宋词,但却由于缺乏近现代的知识,难以将这种作诗能力应用在当今的现实场景之中。
然而基于 Inverse Prompting 的作诗则不同,它起到的作用更像是将预训练语言模型中学习到的作诗能力调取出来,不会受限于题材,因此可以达到一些先前模型难以达到的能力,比如用古体诗为现代题材作诗。
比如开头那篇虹桥机场,显然,虹桥机场是非常现代的概念,从未出现在古诗中,但预训练语言模型从新闻语料中学到了 “虹桥机场” 及其相关的核心特征,进而结合 Inverse Prompting 将作诗的能力发挥出来,从而完成了这样一个全新的作诗命题。这其中,诸如虹桥、夜、灯、月映水帘星、卢浦这样的意象已经到位了,细细读来竟还有一种孤独感和忧伤感。
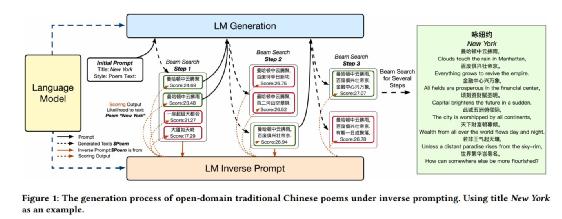
基于InversePrompting的开放域传统中国诗词的生成过程
上文中提到,Inverse Prompting 可以帮助一个语言模型无需精调就能控制文本的生成质量,在符合格式、稳定出诗的情况下得到一些佳句。比如说,通过计算关联度从随机生成的 1000 首诗歌中,挑选出其中质量最高的诗歌。
此时,如果要再改进优质诗歌生成的可能性呢?
这是该研究中的另一个重要贡献:结合 self-training 的强化学习框架(类似于 AlphaGo-Zero 中所采用的方法),将高质量诗歌的生成结果反馈给模型并加以调整,相当于让模型自己朝着生成优质诗歌的方向去训练。如此循坏,便能在 Inverse Prompting 的基础上进一步提高优质诗句的生成概率,降低所需的计算量和候选内容生成量。
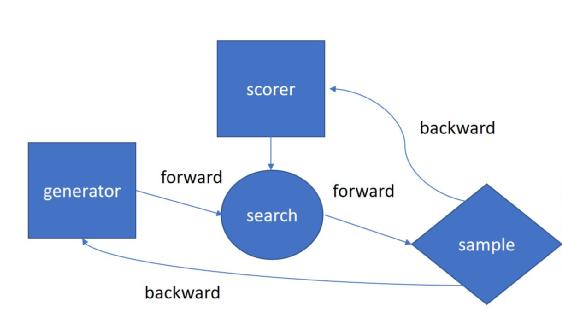 基于搜索的强化学习框架原理示意图
基于搜索的强化学习框架原理示意图如上图所示,其中,生成器会负责生成大量的诗句 candidate,用 scorer 去判断这些诗句的好坏、search 出比较好的诗歌之后,能够得到的较优质的诗歌 sample,它们会比经过比生成器直接生成的要好,再用这些优质的诗歌 sample 去重新 finetune 生成器。
但是,基于搜索的强化学习框架之下,有一个难点在于,如何评判什么样的诗歌算 “好诗”?
团队认为,如果符合格律要求的情况下,能够反映诗歌主旨的诗,便可认为是一首好诗。即,使用诗歌内容去预测标题、能够从内容反推出标题的诗歌,以及在判断两句诗歌是否属于同一首诗、诗内的诗句相互之间被判断属于同一首诗,而诗内诗句与其他诗歌的诗句判断不属于同一首诗的,都算好诗。
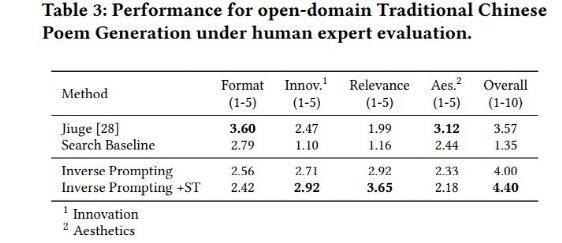
最终,结合了 Inverse Prompting 和 self-training 为模型赢得了 4.40 的平均总分。
3
新的诗歌图灵测试
基于此次的研究成果,团队还进行了一次有趣的诗歌图灵测试实验。在这个诗歌图灵测试实验中,人类玩家需要对模型生成的诗歌和人类生成的诗歌进行分辨。
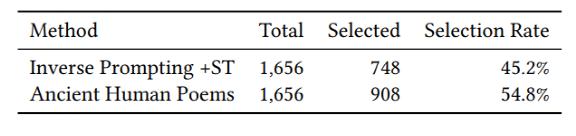
测试总共生成了 1500 首诗歌,并为每次测试随机显示在内的 5 对诗歌(真实古诗 + 生成古诗)。370 个玩家产生的 1,656 个游戏记录显示,45.2% 的用户难以辨别模型生成的诗歌。这一结果表明,结合了 Inverse Prompting 和 self-training 方法的诗歌生成质量,对于普通的在线用户来说可能接近人类水平。
现在,这个面向所有人开放的诗歌图灵测试应用:https://wudao.aminer.cn/turing-test/v1/。
这个诗歌图灵测试中,你可以选择不同的挑战难度。
Easy 模式将会展现 5 组诗歌(包括标题、作者及内容),每组包括 1 首由诗人创作的诗歌和 1 首 AI 创作的诗歌,你需要选择你认为的由人创作的诗歌。所有组选择完成后,你将会得知有多少组结果正确。
此外还有 Hard、Lunatic、Extra,测试难度依次增加。例如,Hard 模式将会展现 10 组诗歌(包括标题及内容),每组包括 1 首由诗人创作的诗歌和 2 首 AI 创作的诗歌,且每组回答限时 60 (绝句)/90 (律诗) 秒。
这个过程或许能丰富你对于诗歌这一古老文艺创作的理解,甚至收获 AI 作诗创造创造出来的新的审美情趣。
当然,正如人类作诗的水平也不能说到达顶峰一样,Inverse Prompting 方法的奏效,不会是作诗 AI 的终点。
虽然 Inverse Prompting 的预训练模型能够很好地理解题材内容,并用诗词的方式将其表现出来,但它能否真正学习到人类对于诗歌韵律乃至意境的形而上的思考与追求?
这仍是一个未解之谜。
至少在著名科幻作家刘慈欣的笔下,情况不太乐观。他写过一篇名为《诗云》的科幻短篇故事,探讨的是技术和艺术,尤其是技术对艺术的解构问题 —— 即人类文明中的美学追求是可以用计算来实现的吗?
故事描述了一种神级文明,人类在这种神级文明眼中好比杂草尘埃。
正当人类主角在某种垃圾焚化装置中拼命挣扎时,口袋里掉出了几篇古诗抄录纸,精巧而工整的字符矩阵意外引发神的注意。神借此学习了汉语的数据库以及有关地球历史的一切知识,很快边制作出了 “诗云”—— 一个可以统计出来符合审美的最优解的强大计算机器,但最后,由于无法鉴别出有价值的诗歌,所有的诗歌在诗云中盘旋。
体验过诗歌图灵测试之后,你又会如何书写 “诗云” 故事的新结尾?


