
最近,AI 圈又炸了!斯坦福大学李飞飞团队联合华盛顿大学的研究人员,用不到 50 美元的云计算费用,训练出了一个名为 s1 的 AI 推理模型。据称,这个模型在数学和编码能力测试中,表现与 OpenAI 的o1 和 DeepSeek 的 R1等顶尖推理模型不相上下。
消息一出,瞬间引发了广泛讨论:50 美元就能复刻 DeepSeek R1?这到底是 AI 领域的重大突破,还是媒体过度炒作的噱头?今天,我们就来深度解析一下这项研究,看看它到底意味着什么。
一、50 美元背后的真相:低成本训练的“秘密武器”
1. 低成本的核心:基座模型与蒸馏技术
首先,我们需要明确一点:s1 模型并不是从零开始训练的。它的低成本训练建立在阿里云通义千问(Qwen2.5-32B-Instruct)这一开源基座模型之上。

研究团队通过蒸馏技术,从谷歌的Gemini 2.0 Flash Thinking Experimental模型中提炼知识,并结合精心筛选的 1000 个高质量推理问题(s1K 数据集),对 Qwen 模型进行了监督微调(SFT)。这种“小数据+强蒸馏”的策略,让 s1 在极低的成本下实现了性能跃升。
2. 训练成本的计算
根据论文,s1 的训练仅使用了 16 块 NVIDIA H100 GPU,耗时 26 分钟。如果按云服务租赁价格计算,确实只需要几十美元。

但需要注意的是,这里的成本仅包括 GPU 算力费用,并不包括基座模型 Qwen 的训练成本(通常需要数百万美元),以及人力、数据筛选等其他隐性成本。因此,50 美元更多是一个“噱头”,实际意义在于展示了如何通过优化训练方法大幅降低成本。
但是相比于之前闭源大模型动辄上千万美元的GPU算力费用,S1的进步是显而易见的。
二、s1 模型的性能表现:真的能媲美 DeepSeek R1 吗?
1. 特定任务上的优异表现
在竞赛数学问题(如 AIME24 和 MATH500)上,s1-32B 的表现确实令人惊艳:它比 OpenAI 的o1-preview高出 27%,接近Gemini 2.0的水平。
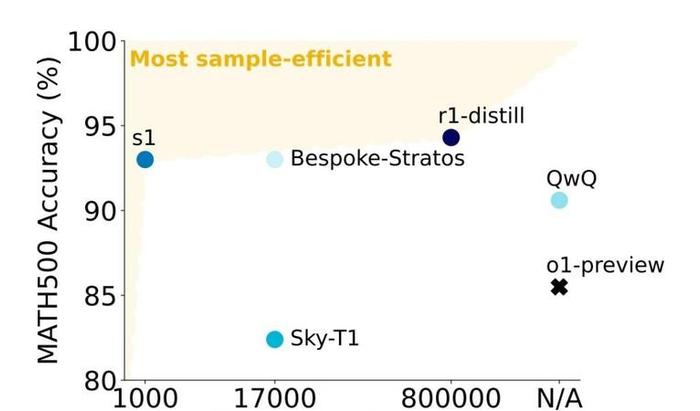
这种优异表现主要归功于两个关键因素:
- s1K 数据集:1000 个高质量问题,涵盖数学竞赛、博士级科学问题等,经过严格的难度、多样性和质量筛选。
- 预算强制法(Budget Forcing):通过控制模型在测试时的计算量(如插入“Wait” token 延长思考时间),s1 在特定任务上表现出了更强的推理能力。
2. 与 DeepSeek R1 的差距
尽管 s1 在特定任务上表现优异,但与 DeepSeek R1 相比,仍有明显差距:
- 通用性不足:s1 的表现主要集中在数学推理任务上,而 DeepSeek R1 则覆盖了更广泛的场景,如金融建模、工程计算等。
- 依赖外部模型:s1 的推理能力依赖于 Qwen 和 Gemini 的知识迁移,而 DeepSeek R1 采用全自研技术链,具备独立迭代能力。
因此,s1 并不能完全复刻 DeepSeek R1,更多是在特定任务上实现了低成本的高性能推理。
三、低成本训练的局限性:AI 普惠的曙光还是昙花一现?
1. 依赖强大基座模型
s1 的成功离不开 Qwen 这一强大的基座模型。如果没有这样的基座,仅靠 1000 个样本数据,很难训练出具备推理能力的模型。
这也引发了一个问题:基座模型的开发者是否应该获得更多回报?如果越来越多的研究依赖于开源基座模型,如何确保 AI 技术的公平使用和共享,将成为业界需要探讨的重要议题。
2. 数据量的局限性
s1 的训练仅使用了 1000 个样本数据,这在大多数复杂任务场景中是不够的。虽然研究团队通过精心筛选数据实现了高性能,但这种方法的可扩展性仍有待验证。
3. 对 AI 产业的影响
s1 的低成本训练模式,为中小团队参与 AI 研发提供了新的可能性。它打破了算力壁垒,让更多开发者能够参与到 AI 军备竞赛中。
但同时,这种模式也可能对大型 AI 公司的研发投入构成挑战。如果顶级模型可以轻易被复刻,那么这些公司的技术积累和商业价值将如何保障?
四、未来展望:低成本 AI 训练的新方向
1. 小数据+强蒸馏:AI 普惠的关键
s1 的研究展示了“小数据+强蒸馏”策略的潜力。未来,随着基座模型的不断优化和蒸馏技术的进步,我们或许会看到更多低成本、高性能的 AI 模型问世。

2. 测试时计算扩展:提升模型性能的新范式
s1 采用的预算强制法,为测试时计算扩展提供了新思路。通过控制模型的思考时间和计算量,可以在不增加训练成本的情况下,提升模型的推理能力。

3. 开源生态的繁荣
阿里云通义千问等开源模型的成功,为 AI 普惠奠定了基础。未来,开源社区或将涌现更多低成本垂直模型,推动 AI 技术的普及和应用。
五、总结:50 美元的启示
李飞飞团队的这项研究,虽然不能完全复刻 DeepSeek R1,但它为 AI 领域提供了新的思考方向:如何在保证性能的前提下,大幅降低训练成本。

对于开发者而言,这是一次技术普惠的尝试;对于行业而言,这是一场关于 AI 研发模式的深刻变革。未来,随着技术的进步,我们或许真的能够看到更多“低成本、高性能”的 AI 模型,飞入寻常百姓家。
你怎么看待这项研究?欢迎在评论区分享你的观点!


财经自媒体联盟













































 第一财经日报
第一财经日报  每日经济新闻
每日经济新闻  贝壳财经视频
贝壳财经视频  尺度商业
尺度商业  财联社APP
财联社APP  量子位
量子位  财经网
财经网  华商韬略
华商韬略 
4000520066 欢迎批评指正
All Rights Reserved 新浪公司 版权所有
