

由于全卷积网络(Fully Convolutional Network, FCN)架构的快速发展,深度学习在语义分割方面取得了里程碑式的进展。大多数方法采用全监督学习方案,需要大量带注释的数据进行训练。尽管它们可以实现良好的性能,但它们数据饥渴的性质需要大量的像素级图像标注。
为了缓解这一问题,特斯联首席科学家邵岭博士及团队,提出了一个用于小样本语义分割的框架,在给定少量像素级标注的支持集(Support)图像的情况下,分割查询集(Query)图像中的目标物体。相关研究成果已于2022年CVPR发表,题为《学习用于小样本语义分割的非目标知识》(Learning Non-target Knowledge for Few-shot Semantic Segmentation)。
1
现有小样本语义分割受局限
挖掘消除非目标区域或可有效减少假正类预测
现有的小样本语义分割研究仅侧重于挖掘目标物体信息,然而往往难以分辨易混淆的区域,尤其是包含背景(Background,BG)和干扰物体(Distracting Objects,DO)的非目标区域。
目前已有诸多研究在探索各种深度学习方法用于小样本语义分割。这些方法通常首先从查询集(Query)图像和支持集(Support)图像中提取特征,然后使用支持集(Support)的掩码提取特定于类的表征。最后,利用匹配网络使用类表征来分割查询集(Query)图像中的目标物体。其中最典型的是,原型学习方法在支持集(Support)图像的目标物体区域上使用掩码平均池化(Masked Average Pooling,MAP)来形成单个或几个原型。然后,通过密集特征匹配,使用原型对查询集(Query)图像中的目标物体进行分割。
虽然现有研究方法已经取得了一些成果,但这些方法都侧重于尽可能从支持集(Support)中挖掘出更有效的物体信息,然后将该信息转移到查询(Query)图像中以实现分割。然而,前述方法经常在有背景(BG)和隶属其他类别共存的物体,即干扰物体(DO)时出现假正类(false positive)的预测。误报的主要原因是在小样本的设定下仅关注目标物体导致相关模型难以学习有判别力的特征和区分易混淆的区域。

此前的方法经常在非目标区域显示假正类预测。红色像素表示目标物体,绿色像素表示假正类预测。

现有框架与团队提出的小样本分割框架对比:主要区别在于前者仅挖掘目标类别信息,而邵岭博士团队提出了消除属于非目标区域的共存像素,包括背景(BG)和干扰物体(DO)。
为了缓解前文所提到的问题,团队从一个全新的角度重新思考小样本语义分割任务,即挖掘和排除非目标区域(BG和DO区域),而不是直接分割目标物体。从这一点出发,在该研究中,团队提出了一种全新的框架——用于小样本语义分割的非目标区域消除(Non-Target Region Eliminating, NTRE)网络。
团队首先开发了一个BG挖掘模块(BG Mining Module, BGMM)来获得一个BG原型并分割BG区域,然后提出了一个BG消除模块(BG Eliminating Module, BGEM)来从查询(Query)特征中过滤掉BG信息。接下来,支持中的目标原型在匹配网络中用于激活查询特征中的目标对象。随后,团队采用DO消除模块(DO Eliminating Module, DOEM)先挖掘DO区域,然后从查询(Query)特征中过滤掉DO信息。如此一来,即可在不受BG和DO区域干扰的情况下获得准确的目标分割结果。
在BGMM中,获得BG原型并不像获得支持原型那么简单。考虑到BG区域普遍存在于几乎所有图像中——例如天空、草地、墙壁等等——团队建议同时从训练集中的查询(Query)和支持(Support)图像中学习一个通用的BG原型。基于这个原型,团队可以很容易地分割所有图像的BG区域。由于没有真实的BG分割掩码来监督模型学习,团队专门设计了一个基于已知目标分割掩码的BG挖掘损失。
另外值得注意的是,考虑到很难学习到一个好的嵌入空间原型特征来区分在小样本设置下的DO和目标物体,团队提出了原型对比学习(PCL)方法,通过细化原型特征嵌入来提高网络的物体识别能力。具体来说,对于一个查询(Query)目标原型,团队将相应的支持(Support)目标原型视为正样本,而将查询(Query)和支持(Support)中的DO原型视为负样本。接下来,团队提出一个PCL损失函数来强制原型嵌入在目标原型中相似,而在目标原型和DO原型之间不相似。这样一来,PCL可以有效地帮助网络区分目标物体和DO。
总体而言,该研究成果有以下多项亮点:
该研究是首次挖掘和消除包含BO和DOs的非目标区域用于小样本语义分割领域。这一进展可以有效地减少假正类的误判。
团队提出了BGMM、BGEM和DOEM以有效地实施BG和DO区域的挖掘和消除。团队还提出了一种新的BG挖掘损失函数,用于在不使用真实的BG的情况下训练BGMM。
团队提出了一种PCL方法来提高模型能力,以便更好地区分目标物体和DO。
基于PASCAL-5i和COCO-20i的大量实验表明,团队提出的框架实现了全新的SOTA性能,尤其是在1-shot setting中。
2
大量实验结果验证
全新学习方法有效提升小样本语义分割性能
该研究成果得到了大量实验验证。
PASCAL-5i:图表1展示了团队所提出方法与几个代表性模型在PASCAL-5i上的性能比较。可以看到,在所有三个主干网络(即 VGG-16、Resnet-50 和 Resnet-101)上,该方法在 mIoU 和 FB-IoU 方面都大大优于所有过往模型。
具体而言,在1-shot setting下,该方法在使用VGG-16、Resnet-50 和 Resnet-101 的骨干上的平均 mIoU 分数分别为 59.0、64.2 和 63.7,比SOTA分别提升1.2%、3.4% 和 1.8%。同时,在 FB-IoU 方面,我们的方法在三个骨干上分别比之前的最佳结果提升 1.1%、5.0% 和 3.3%。在5-shot setting下,我们的方法在 mIoU 方面仅在 VGG-16 骨干上获得了最佳结果,但在所有三个骨干上分别比之前最先进的 FB-IoU 结果提升了 2.6%、5.7% 和 1%。
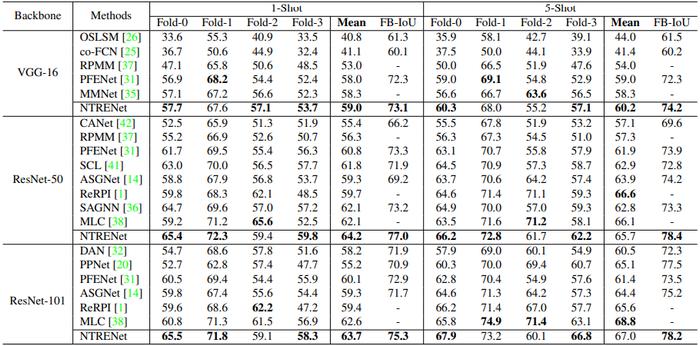
图表1:PASCAL-5i上四层的 Class mIoU 和 FB-IoU 结果。“Mean”结果为所有四个 mIoU 分数的平均数。此表中省略了详细的FB-IoU 结果。粗体表示为最佳结果。
COCO-20i :尽管COCO-20i 为更具挑战的数据集,包含大量含有真实场景的图像,但如图表 2 所示,该方法仍然实现了优越的性能。延续之前的工作,该方法仅使用 Resnet-50 和 Resnet-101 骨干。
图表2 显示,团队所提出的方法在1-shot setting设置下分别在两个骨干上产生了 39.3 和 39.1 的平均 mIoU 分数,分别比此前的最佳结果高出 4.8% 和 5.7%。5-shot setting设置中,尽管场景颇具挑战,FB-IoU 结果也验证了这一方法的优越性。
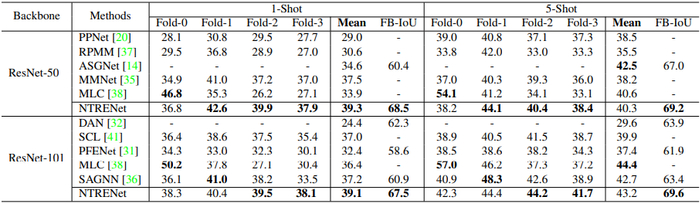
图表2:COCO-20i上四层的 Class mIoU 和 FB-IoU 结果。“Mean”结果为所有四个 mIoU 分数的平均数。此表中省略了详细的FB-IoU 结果。粗体表示为最佳结果。
限制:团队发现,与此前的SOTA相比,新模型的平均mIoU结果在5-shot setting设置中未取得明显优势。团队判断此为合理结果,因为新提出的方法主要侧重于消除非目标区域而不是分割目标物体。因此,支持(Support)样本的数量从1个增加到5个,并不能为该方法引入额外的非目标信息。尽管如此这一方法仍能为未来的工作提供一个与传统方法相反的新视角。
定性比较:图表3中展示了新方法生成的预测分割掩码与专注于分割目标物体的典型传统模型,即 PFENet的定性比较。可以看到由于非目标区域的干扰,PFENet 无法准确分割目标物体。然而,团队提出的NTRENet可以在BG和DO区域中以更少的假正类预测获得更准确的结果,从而清楚地证明了方法的有效性。

图表3:PCL上负样本的结果比较。单样本设置下PASCAL-5i上的mIoU结果。
总体而言,团队从新视角解决了小样本语义分割的问题,并提出了全新的NTRE框架来关注BG和DO区域。团队提出了BGMM、BGEM 和DOEM 来有效地实现对BG 和DO 的挖掘和消除。尤其值得注意的是,团队提出了BG挖掘损失函数,在不使用真实的BG的情况下来监督BGMM和一个BG原型的学习。此外,团队还提出了PCL来提高模型能力,以更好地区分目标物体和 DO。在两个基准数据集上进行的大量实验证明了这一方法相较于过往方法的性能优势。
头条号入驻


4000520066 欢迎批评指正
All Rights Reserved 新浪公司 版权所有
