

从数据库到临床应用,如何用 AI 解读生命密码?
作者|吴彤
编辑|麦广炜
在生物医学研究的前沿领域,“单细胞蛋白质组学”是怎样的存在?
用一个比喻来说,它就像一把钥匙,能够开启细胞内部世界的大门,让我们得以窥见细胞如何通过蛋白质的相互作用来执行生命活动。
这一研究领域的突破,不仅能够推动科学界对生命过程的理解,也为精准医疗的实现奠定了基础。
近期,腾讯的 AI Lab,无疑成为了这一前沿研究领域率先“揭开英雄榜 ”的那个研究机构。
3月20日,腾讯 AI Lab 的 3 篇蛋白质组论文正式入选国际顶级学术期刊。论文分别在数据库、AI 建模、AI 辅助临床三个角度提出了全新的研究方案,为人类从根本上阐释生命提供了重要技术参考。
《SPDB: a comprehensive resource and knowledgebase for proteomic data at the single-cell resolution》 ,被生物信息学领域数据库方面的的权威期刊 Nucleic Acids Research收录。
《 scPROTEIN: a versatile deep graph contrastive learning framework for single-cell proteomics embedding》,被Nature旗下的方法学期刊Nature Methods收录。
《Deep domain adversarial neural network for the deconvolution of cell type mixtures in tissue proteome profiling》,被Nature旗下机器学习专业期刊 Nature Machine Intelligence 所收录。
借此契机,雷峰网-AI科技评论近期对话腾讯 AI Lab 科学家姚建华和研究员杨帆,他们是三篇论文的共同作者。在访谈中,他们深入阐述了这些论文背后的技术突破、应用价值和未来的研究规划。
他们解释道,这三篇论文的创新之处在于,它们首次为单细胞蛋白质组提供了全面的数据知识库和系统的AI分析方法。
论文一中建立的 SPDB 数据库,通过标准化处理不同来源的单细胞蛋白质组学数据,使得数据易于比较和分析,是目前全球数据量最大、覆盖技术和数据集最为广泛的单细胞蛋白质数据库。
论文二中的 scPROTEIN 框架,针对单细胞蛋白组数据的特殊性提出了解决方案,能够处理数据中的不确定性、缺失值、批次效应和噪声问题。为基于单细胞蛋白质组的肿瘤发生发展机制研究、药物靶点发现和肿瘤早筛和微环境研究提供重要的AI辅助作用。
第三篇论文中提出的 scpDeconv 方法,是一种全新的反卷积方法,能够从“组织蛋白质组”数据中挖掘出特定细胞类型比例,为肿瘤辅诊和预后分析提供了新的视角,是三篇论文中与临床应用最为贴近的一项成果。
姚建华,作为腾讯 AI Lab 的 AI 医疗首席科学家,补充道:“AlphaFold 在蛋白质结构领域取得了令人瞩目的成就,它主要关注单个蛋白质的结构和功能,或几个蛋白质之间的相互作用。而我们的研究则聚焦于细胞内所有蛋白质的表达模式,这些信息反映了整个细胞的状态和微环境,使我们的工作更加贴近临床应用和疾病机制的探索。”
值得一提的是,当我们在讨论论文成果的同时,一个更深远的议题逐渐浮现:成立于2016年的腾讯 AI Lab,是否有能力在接下来的五年中,引领生命科学领域的未来发展?
这个问题不仅考验着实验室的科研实力,也反映出科技公司在生物医学领域的影响力和责任。如今的腾讯 AI Lab,走的每一步都比以往更受关注。
以下为对话(经编辑):
1
数据、建模、应用,「三管齐下」
雷峰网:首先请两位介绍下,三篇论文的创新点,简要介绍技术实现形式,应用价值,以及对单细胞蛋白质组学这一研究领域的贡献(比如最适合哪些人/机构使用)。
杨帆:单细胞测序技术已经取得了飞速发展,尽管单细胞转录组相关的测序技术和计算方法已经相当成熟,但转录水平与蛋白质水平的相关性通常低于 50% 。在单细胞层面,这种相关性更低。
因此,只有通过研究蛋白质组,我们才能深入理解生命活动和疾病的本质。
单细胞蛋白质组测序技术也在不断进步,技术革新层出不穷,并受到了国际顶级期刊如 Nature Methods 的关注和报道。特别是以 SCOPE-MS(Single-Cell Proteomics by Mass Spectrometry)、nanoPOTS (nanodroplet processing in one pot for trace samples) 为代表的基于质谱的蛋白质测序技术,能够检测到单细胞中数千种蛋白质的存在。这比以往基于抗体的单细胞蛋白质组测序技术有了显著的提升。
然而,这些数据的复杂性,使得专门针对单细胞蛋白质组数据的AI计算方法相对缺乏。
正是基于这一背景,我们的三篇论文围绕单细胞蛋白质组数据分析进行了深入研究。我们首次为单细胞蛋白质组提供了一套系统的 AI 分析方法和数据知识库。
其中,第一篇论文收集了目前世界上最全面的、不同来源、不同测序技术、不同物种的单细胞蛋白质组数据,并进行了标准化处理和系统性评估。
第二篇论文基于迁移学习技术,从单细胞蛋白质组数据中推断组织蛋白质组中的细胞比例;
第三篇论文则采用对比学习方法对单细胞蛋白质组进行表征;
我们的计算方法通过实验验证,明显优于直接应用单细胞转录组的方法。这些方法已经开源,并配备了详尽的使用说明,可供全球范围内的研究人员使用。
我们的算法特别适合那些从事单细胞蛋白质组数据生成的团队,他们可以直接应用我们的技术进行细胞级别的数据分析和下游应用。
对于临床医学专家而言,他们可以利用我们的反卷积算法分析公开的TCGA或CPTAC等蛋白质组数据库,或者基于自己收集的临床组织样本,以深入理解肿瘤微环境,辅助疾病机制的研究和诊断预测。
此外,我们的数据库允许生物学家和医学工作者在线探索他们感兴趣的蛋白质或细胞类型,观察这些蛋白质在不同细胞类型中的变化规律,从而支持他们在特定蛋白质研究方向上的研究。
雷峰网:因为三篇论文成果都是集中在单细胞蛋白质组学领域,探讨了如何通过不同的计算方法和数据库资源来分析和理解单细胞水平上的蛋白质表达数据。
那么,在此之前你们做了哪些工作?在三篇论文成果出来后,紧接着有哪些研究计划?
杨帆:在此之前,我们团队已经进行了大量工作,包括医学多模态数据分析、疾病预测以及精准医疗等领域的研究。同时,我们也在单细胞转录组和空间组学等生命科学基础计算领域进行了深入探索,并在多个AI顶级会议和期刊上发表了相关论文。
因此,我们在医学、生命科学、精准医疗和数据分析等领域积累了丰富的经验。
举个例子:
我们在预训练语言模型尚未广泛应用于单细胞数据分析领域时,就意识到预训练模型在自然语言处理(NLP)领域已经取得了巨大成功。当时,单细胞数据分析主要依赖于简单的机器学习方法,并且常常需要针对每个数据集进行手工处理,这限制了模型的泛化能力。
针对这一问题,我们在 2021 年启动了一个项目,设计了一种基于单细胞数据的大规模预训练语言模型,名为scBERT。我们根据单细胞数据的特性,开发了基因嵌入(gene embedding)和表达嵌入(expression embedding),使得这些数据能够被 Transformer 这种先进的计算模型处理和识别。
我们首次引入了 BERT这种预训练和微调的范式,从而充分利用了当时尚未充分利用的大规模单细胞数据进行预训练,显著提升了模型的泛化性和处理跨批次、跨数据集数据的能力。
这一成果发表在了 Nature Machine Intelligence上,开启了单细胞大模型研究的新篇章。
在这三篇论文发表之后,我们计划更加聚焦于重大科学问题的研究,并注重其临床应用和转化。我们将进一步整合多组学数据和蛋白质大模型,赋能更多的应用场景。
姚建华:我可以补充一些背景信息。
众所周知,生物体内的核心法则是中心法则,即 DNA、RNA 和蛋白质之间的关系。
DNA 携带遗传信息,通过转录成为 RNA,形成转录组。
而RNA进一步翻译成蛋白质,即蛋白质组。
我们的研究工作正是基于这一原理。基因测序技术的发展历程显示,DNA 测序是相对容易的部分,而 RNA 和蛋白质的测序难度逐渐增加,因为它们需要更复杂的扩增和测量技术。
从上个世纪 70 年代开始,人类基因组测序技术已经经历了几代的发展。
最初,人类主要关注 DNA 信息的测序。大约 10 年前,单细胞技术开始兴起,最初主要集中在 RNA 信息的测序。而单细胞蛋白质组学则是最近五六年才开始发展的新兴技术。
我们的研究工作也是沿着这一脉络逐步推进的,从较简单的数据开始,逐步过渡到更复杂的数据分析。
例如,我们之前的工作 scBERT 主要针对转录组数据进行分析。而现在,我们进一步研究蛋白质组数据,这是一个更为复杂和具有挑战性的领域。随着数据难度的增加,对算法和计算能力的要求也越来越高。我们的研究正是在这一背景下不断进步和发展的。
雷峰网:总体从技术层面来说,论文一提供了一个数据资源库,论文二和论文三则分别提出了新的深度学习框架来处理不同类型的数据分析问题。论文二侧重于通过图学习处理单细胞蛋白质组数据,而论文三侧重于使用域对抗神经网络进行细胞类型比例的解卷积。
不知道我这样理解是否正确,请两位再介绍下三篇论文的联系与区别。以及,全球范围内,还有哪些课题组或企业在做类似的工作?
杨帆:您的理解非常准确。
数据资源库是算法研究的基石,我们深知AI算法的发展离不开数据的支撑。在单细胞蛋白组学领域,数据的准确表征是进行下游应用的关键。
掌握了单细胞蛋白组数据后,我们能够详细了解每种细胞类型在细胞内蛋白质表达的模式。
基于这些数据,结合AI算法,我们可以进一步推断组织蛋白组中细胞类型的比例,这对于理解肿瘤微环境至关重要。
目前,临床上已有大量基于组织蛋白组的数据,这些数据通常来源于肿瘤患者癌组织及其周围正常组织的样本,通过质谱技术获得的是多种细胞类型混合后的蛋白质表达平均水平。
我们的反卷积算法能够精确推断出不同细胞类型的比例,使全球研究者能够从公开数据集中挖掘出有关细胞比例的信息,从而更好地理解肿瘤微环境。
此外,即使在无法进行单细胞蛋白组测序的临床情况下,我们的算法也能提供一种解决方案,帮助理解细胞微环境,从而辅助临床进行疾病预后和预测。
这三篇论文可以视为一个整体,其中数据资源库为基底,上面有两个不同角度的AI应用,如同一棵大树上结出的两个果实。
据我们所知,目前全球范围内尚无其他团队或企业开展与我们完全相同的工作。其他机构主要在进行单细胞转录组或蛋白质结构的研究,这些研究当然也很重要,但我们的工作填补了单细胞蛋白组学领域的一个空白,具有创新性和前瞻性,未来必将吸引更多研究聚焦于此领域。
姚建华:正如杨帆所提到的,蛋白质结构在AI领域中,尤其是 AlphaFold 这样的技术最为人所熟知。
AlphaFold 主要分析的是单个蛋白质的结构,例如蛋白质的折叠方式或几个蛋白质之间的相互作用,它关注的是单个蛋白质的三维结构,以及其功能和对人体细胞的作用。
而我们的研究则是从另一个角度出发,分析细胞内所有蛋白质的表达模式。我们知道,人体有数以亿计的蛋白质,即使是单个细胞内也有成千上万的蛋白质。我们的目标是分析这些蛋白质之间的相互作用和表达模式,这些信息反映了整个细胞的状态和微环境。
通过蛋白质组或转录组等组学数据,我们可以更全面地理解细胞的微环境和疾病产生的原因,这对于临床治疗和疾病机制的研究具有重要意义。
与 AlphaFold 等关注单个蛋白质结构的技术相比,我们的研究更侧重于整个细胞和微环境的系统性分析,这使得我们的工作更接近临床应用和疾病机制的探索。
雷峰网:虽然是三个论文成果,但其实是在一个研究项目之中的吗(因为研究是顺着数据库、AI建模、AI辅助临床三个层面逐一展开)?三篇论文的作者团队在专业背景上有何区分?整体来说,从立项到出论文成果,持续时间多久?
杨帆:这三篇论文是在同一个大的研究方向下自然展开的。主要作者包括我和姚老师。
此外,我们的团队还包括来自不同领域的合作者,如生物信息学和 AI 机器学习领域的专家,以及校企联合培养的学生。
腾讯 AI Lab 作为一个跨学科的平台,为跨学科AI应用提供了丰富的土壤。实验室汇集了 数百位顶尖科学家,这为我们的研究提供了强大的支持。
在 AI Lab,我们有来自生物信息学领域的研究员,他们从生物医学问题出发,收集数据并定义研究问题。
在模型研发阶段,尤其是面对原创性研究中的新问题和挑战时,我们需要AI技术的创新。在这方面,我们有AI领域世界顶级的科学家与我们合作,共同应对图模型、可信 AI 以及迁移学习等领域的挑战。
正是在 AI Lab 这样一个充满世界级专家、紧密交流和跨学科合作的环境中,我们才能够激发出创新的火花,并推动一系列跨学科AI应用研究的发展。
我们的实验室主任张正友老师和AI医疗首席科学家姚建华博士,分别是 IEEE Fellow 和 AIMBE Fellow,ACM fellow,是世界知名的学术领袖。在他们的指导和把关下,我们的研究员在进行科研和创新时更加自信和从容。
一般来说,我们的项目从启动到成果发表大约需要一年到一年半的时间。
雷峰网:杨帆博士,您的背景和经历是怎样的?同时请问姚建华老师,如今腾讯 AI lab 的工作者在专业背景上有何共性?
杨帆:我是清华大学的博士毕业生,在博士期间主要从事临床组学分析的研究。自2016年起,我开始接触人工智能领域。博士毕业后,我加入了腾讯随后在 AI Lab 做研究,至今已近六年。在这里,我相当于又完成了一个 AI 领域的博士学位,进行了广泛的AI研究。
我感觉自己的知识结构像是“T”字型。
一方面,在组学生物数据分析领域有深入的研究和超过十年的经验;
另一方面,在AI领域,包括多模态研究、医学影像、临床文本数据处理、图模型、深度学习等多个方面都有所涉猎,并发表了相关论文。
这种“一专多能”的背景使我在跨学科领域,如 AI for Science ,能够提出独特的见解和研究方向。
姚建华:我们团队确实需要这样的跨学科人才。正如杨帆所提到的,AI Lab 涵盖了人工智能、机器学习、语音识别、多模态等多个研究方向。我们特别注重生命科学领域的人工智能应用,因此团队中的许多研究员都具备 AI 和生物学的双重背景。
只有通过这样的交叉合作,才能真正推动这一领域的发展。我们也经常与其他专注于人工智能的团队进行技术上的交流和探讨,共同促进科学的进步。
2
三篇论文逐一追问:
好在哪、不足在哪、给谁用?
|论文一:《SPDB: a comprehensive resource and knowledgebase for proteomic data at the single-cell resolution》
链接:https://academic.oup.com/nar/article/52/D1/D562/7416372
 该论文已入选生物信息学领域数据库方面专业期刊 Nucleic Acids Research
该论文已入选生物信息学领域数据库方面专业期刊 Nucleic Acids Research雷峰网:SPDB 如何整合不同来源和技术的单细胞蛋白质组学数据?团队在数据库设计和实施过程中遇到的主要挑战及解决方案。还有哪些研究不足和优化计划?
杨帆:SPDB旨在为不同技术类型的单细胞蛋白组学数据提供一个专门的数据处理框架。
我们通过在统一的环境中对来自不同基础来源的数据进行标准化处理和分析,使得用户能够在一个平台上对比和探索不同技术来源的数据。
为了确保数据集的独立性和可靠性,SPDB 并没有直接整合不同来源的数据集,而是提供了对单个数据集的独立探索功能,以及对同一蛋白质在不同数据集中的对比探索。
在SPDB数据库建设的初期,我们面临的一大挑战是:如何处理和分析一些我们之前未曾接触过的数据类型。
例如质谱蛋白质组数据,以及这些原始数据的处理程度和存储格式的多样性。
我们通过广泛阅读相关文献,并详细研究每个数据集的源文献中关于数据处理的描述,为每个数据集制定了针对性的数据处理步骤,从而确保了数据的准确性和可靠性。
目前,SPDB 的一个不足之处在于:缺乏在线工具供用户直接使用。未来,我们计划将研究团队开发的相关算法集成到SPDB平台上,以便用户能够更方便地使用这些工具。
此外,SPDB 目前还没有提供蛋白质对应的基因表达信息,即转录组数据。因此,我们的后续工作将包括为蛋白质表达提供相应的基因表达数据,以便于用户进行更全面的对比展示和分析。
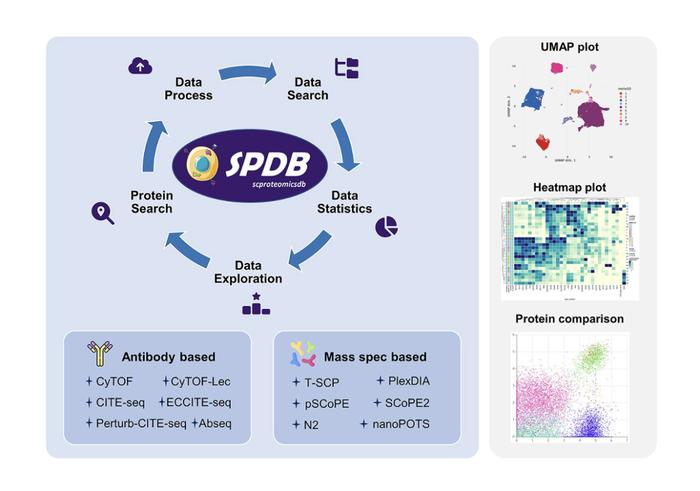 SPDB数据库 概述图
SPDB数据库 概述图雷峰网:在我的理解,这应该是这一工作的最大贡献,是收集了大量数据,还对这些数据进行了标准化处理,使得不同来源的数据可以放在一起比较和分析。这就好比把不同语言的书籍翻译成同一种语言,让读者更容易理解。为什么当下这种工作成为必要?
杨帆:您的理解非常准确。我们构建这个数据库的初衷,是因为单细胞转录组和空间组学领域的研究已经日益成熟,积累了大量的数据。
市场上也存在一些对单细胞转录组和空间组数据进行整合和统计的数据库,这些数据库不仅为生物学家和临床工作者提供了探索和发现的工具,也为生物信息学研究者提供了基于标准化数据进行算法开发的平台。
由于许多研究者更倾向于使用已经处理好的标准化数据进行开发,而并非所有人都具备从大量分散的原始生物学文献中提取数据的经验或知识,我们的论文和工作的目标就是为单细胞蛋白组学领域做出贡献。
我们希望通过标准化的数据,让更多的AI研究者和生物信息学工作者能够看到单细胞蛋白组学数据的潜力,并在此基础上进行算法的研发和创新。
这就像是为整个单细胞蛋白组学研究社区提供了一片沃土,让更多创新得以孕育。
此外,这个数据库也为那些日常工作繁忙、非生物信息学专长的生物科学工作者和医疗工作者提供了便利。有了这个实用的工具,他们可以从单细胞蛋白组学的角度获得新的启示和发现,即使这不是他们的主要研究领域。
姚建华:建立这样一个数据库的工作量非常巨大,数据分散在各个地方。所以这种工作其实非常适合像我们这样资源相对充足的公司来开展。
尤其是在大模型时代,数据的重要性愈发凸显。
以前训练一个模型可能只需要几十万、几百万的数据,但现在训练一个大型模型可能需要数亿的数据量。
我们的数据库已经收集了 3 亿个细胞的数据,这样的数据量才有可能支撑大型模型的训练。我们将持续更新数据库,随着新数据的加入,我们希望这个数据库能够真正为整个领域的发展做出贡献。
|论文二:《 scPROTEIN: a versatile deep graph contrastive learning framework for single-cell proteomics embedding》
链接:https://www.nature.com/articles/s41592-024-02214-9
 已入选 Nature 旗下方法学专业期刊 Nature Methods
已入选 Nature 旗下方法学专业期刊 Nature Methods雷峰网:我的理解是,scPROTEIN 是一种新型的数据分析框架,它能够处理和分析单细胞蛋白质组数据。这就好比我们有了一台超级显微镜,不仅能够看到细胞,还能够看到它们内部的蛋白质如何互动。创新之处在于它能够解决数据中的不确定性、缺失值、批次效应和噪声问题,这些都是以往研究中的难题。
为什么要这么做?还有哪些研究不足,应对办法?
杨帆:scPROTEIN 框架的开发是为了解决单细胞蛋白组数据分析中的独特挑战。
在单细胞蛋白组的测定过程中,从细胞分离、裂解、蛋白质提取,到通过质谱技术进行肽段检测,每一个步骤都可能引入不确定性和噪声。
例如,样本制备的差异、标记策略的不同、质谱仪的状态变化,以及肽段在质谱仪中的离子化和检测过程,都可能导致批次效应和数据中的噪声问题。
此外,与单细胞转录组数据不同,单细胞蛋白组信号无法通过扩增来增强,只能依靠质谱技术的灵敏度来检测微量蛋白。
现有的许多单细胞转录组数据分析方法,并未充分考虑单细胞蛋白组数据的特殊性,直接应用这些方法效果并不理想。
因此,我们提出了 scPROTEIN 框架,它不仅考虑了单细胞蛋白组数据的层次结构,还采用了基于可信度的方法来估计肽段测定的不确定性,并通过图对比学习进行表征和去噪,有效解决了数据中的复杂问题。
经过下游任务的充分验证,scPROTEIN 的性能显著优于现有的单细胞蛋白组数据分析方法和直接套用单细胞转录组的方法。
姚建华:我们的算法实际上提供了一种“数据增强”功能,能够有效去除数据中的噪声和批次效应,使得数据分析更为一致和准确。
此外,我们还提出了一种数据编码的 embedding 方法,这在某种程度上起到了“数据降维”的作用。
正如许多大型模型如 Transformer 和 GPT 所做的那样,通过 embedding ,我们可以将复杂的蛋白质信息以一种高效的方式表示出来。
这种方法不仅能够帮助我们提取数据中的核心信息,还能够揭示不同蛋白质之间的关系,为单细胞蛋白组数据分析提供了一种全新的视角和工具。
雷峰网:其他现有的单细胞数据分析工具,为什么差强人意?
杨帆:正如我们之前提到的,scPROTEIN 框架是专门为解决单细胞蛋白组数据所面临的挑战而设计的。现有的大多数单细胞数据分析工具,并没有专门针对单细胞蛋白组数据的特性。例如数据的层次结构和测量不确定性等,进行优化。
scPROTEIN 框架则完全针对单细胞蛋白组数据的特有问题进行了算法开发,因此能够有效解决这些数据特有的问题。
姚建华:目前而言,几乎没有其他方法专门针对单细胞蛋白组分析。这项技术非常前沿,相关数据也相对稀缺,很少有研究能够收集到如此多的单细胞蛋白组数据。
此外,分析这些数据本身也存在很大的难度,因为数据量大且复杂。
在我们开始这个项目的时候,市场上还没有专门针对单细胞蛋白组的分析工具,大部分工作都是集中在单细胞转录组上。
我们预计在未来几年,研究者们将会更多地关注蛋白质组学,因此我们在这方面的工作实际上是领先一步,提前进行了探索和开发。
|论文三:《Deep domain adversarial neural network for the deconvolution of cell type mixtures in tissue proteome profiling》
链接:https://www.nature.com/articles/s42256-023-00737-y
 已被Nature旗下机器学习专业期刊 Nature Machine Intelligence 所收录
已被Nature旗下机器学习专业期刊 Nature Machine Intelligence 所收录雷峰网:我理解的是,这篇论文的一大亮点:提出了一种新的基于深度学习的解卷积方法(命名为scpDeconv),专门针对蛋白质组数据,获取其中的肿瘤微环境信息。
能否介绍一下scpDeconv在临床诊断和治疗中的应用前景和潜在挑战。scpDeconv方法在实际应用中可能遇到哪些问题,以及是否有解决方案。
杨帆:scpDeconv 的临床应用前景非常广阔。如我们之前提到的,该方法可以挖掘组织样本中的细胞比例信息,从而反映肿瘤微环境的状况。
例如,在我们的研究中,对黑色素瘤样本进行 scpDeconv 分析后,我们发现不同细胞类型比例的患者预后存在显著差异。
这种分析可以作为一种辅助诊断工具,帮助医生预测疾病预后,是精准医疗的一个重要应用场景。
然而,scpDeconv 的潜在挑战在于:单细胞蛋白质组数据的覆盖范围可能不够广泛,包括细胞类型和组织类型。
为了克服这一挑战,我们需要与进行单细胞蛋白质组测序的实验室合作,共同贡献更多的公开数据,以便进行更准确的分析。
姚建华:“组织蛋白质组”分析相对容易进行,因为它基于的是整个组织样本,包括了成千上万个细胞的蛋白质总和,而“单细胞蛋白质组”分析则需要对每个细胞单独进行测量,难度和成本都显著增加。
目前,临床上主要进行的是组织蛋白质组分析,因为成本较低,技术相对成熟。
我们的 scpDeconv 方法,能够从组织蛋白质组数据中解析出细胞类型的异质性,从而提供类似于单细胞分析的结果,尽管可能不如单细胞数据那么精确,但至少能够揭示组织中细胞组成的信息。
这样的技术使得临床医生能够利用现有的数据获得更多的诊断信息,帮助更准确地进行疾病诊断和治疗决策,实现精准医疗的目标。
3
如何对得起大厂
AI lab 的名号?
雷峰网:最后,请说一下,腾讯 AI Lab 在单细胞蛋白质组学领域的未来研究计划。
杨帆:我抛砖引玉,分享一下我们的未来规划。
首先,我们将贯彻和落实我们实验室主任张正友博士的指导思想,更加聚焦于解决世界级的重大科学问题,并在 AI for Science 领域实现 AI Lab 的使命——在学术界产生影响,在工业界创造产出。
我们的研究方向与腾讯公司的“科技向善”愿景相契合。未来,我们将继续利用现有基础,整合单细胞多组学和蛋白质大模型,推动临床应用研究,并致力于产出具有世界影响力的原创AI应用研究成果。
姚建华:我们的工作重点是利用人工智能技术解决实际问题和科学挑战。
作为 AI Lab,我们的优势在于资源的相对丰富性和研究的聚焦性。与高校相比,公司的环境允许我们集中力量进行大规模的研究项目。
此外,公司的组织结构也使得不同领域的研究员能够协同合作,共同推进同一项目。虽然高校的研究环境更为自由,但我们这里的研究可以更加集中和深入。
我们的目标是聚焦于最前沿的课题和方向,解决最具挑战性的问题,以此形成强大的影响力。
我们将继续在单细胞蛋白质组学领域深耕,不仅推动科学的发展,也为临床应用提供创新的解决方案。我们期待通过这些努力,为整个领域带来积极的变化,并为社会做出更大的贡献。
雷峰网:我了解到,腾讯 AI Lab 也在探索脑科学等领域,这是否意味着我们未来可能会看到更多相关成果?
姚建华:我们目前的重点还是集中在生命科学的一些基础问题上,如蛋白质和基因组学等领域。
我们确实进行了一些大脑相关的研究,但主要是为了探索大脑的本质。例如,去年我们进行了大脑图谱的研究,这更偏向于脑科学的基础研究。
我们试图通过蛋白质组学和基因组学的信息来区分不同类型的神经元,并理解它们是如何相互联系和作用的。这样的研究有助于我们深入理解大脑的机制。
通过我们的AI算法分析基因组学和蛋白质组学数据,我们帮助神经科学家对不同脑细胞进行分类,并描绘它们在大脑中的空间位置。这样的大脑图谱研究是神经科学研究的基础。
当然,要真正深入到脑图谱的研究,最终还需要回到基因和蛋白质的层面。我们的目标是支持更高层次的科学研究。
雷峰网:那么三篇论文成果之后,还有关于临床应用和成果转化的规划吗?
姚建华:目前,我们更侧重于研究成果的产出,因为工业产出往往需要更多的资源和工程团队。
我们现阶段主要致力于解决一些基础科学问题。当然,随着技术积累到一定程度,我们可能会通过与其他团队合作或寻找合作伙伴来实现这些技术的落地和产业化。
我们的目标是先在科研领域取得突破,为未来的工业应用打下坚实的基础。
本文作者 吴彤 长期关注人工智能、生命科学和科技一线工作者,习惯系统完整记录科技的每一次进步,欢迎同道微信交流:icedaguniang
头条号入驻


4000520066 欢迎批评指正
All Rights Reserved 新浪公司 版权所有
