
素材来源
AISHELL-1 是中文语音识别学术研究中应用最广泛的数据集,本期基于 AISHELL-1 的测试集,对各厂商进行测试。本场景属于非常干净的学术场景,不会加入后续滚动测试。
场景特点
● 环境
室内,无噪声
● 拾音设备
高保真麦克风,近场
● 说话人
数据集制作过程中邀请的发音人(多人,分布在全国各地)
● 说话方式
根据预先设计的脚本,由发音人对照朗读
语速慢,字正腔圆
● 方言
普通话,个别发音人有轻微口音
● 内容领域
拼写,数字串,控制命令,音乐,娱乐,经济,体育等
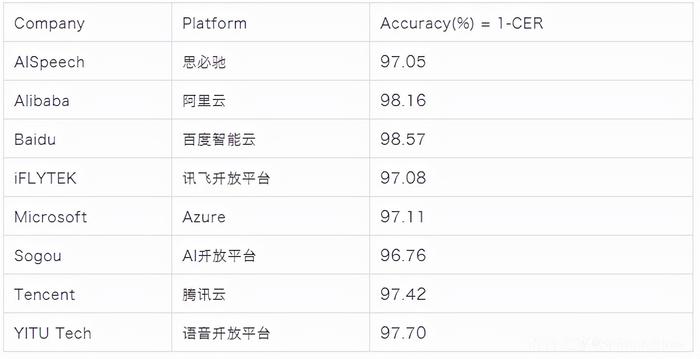
测试结果
测试时间:2021.08
简评
● 根据知名的AI Wiki 网站 PapersWithCode,目前基于AISHELL-1 的学术研究中最好的性能来自于出门问问和西北工业大学的工作 WeNet,其准确率为 95.28% (详情见 https://paperswithcode.com/sota/speech-recognition-on-aishell-1)。从本期的测试可以看到,商业引擎在性能上均远好于单独封闭数据集上的系统。从这点上可以看到数据对于语音识别系统性能的重要性。结合我们的上一期评测 [kaldi_multicn] (最好开源预训练模型 vs 现有的商业引擎),这两篇评测,我们头一次定量的交叉比较了学术、开源模型与现有的商业引擎的差距。
● 值得一提的是,百度在复杂、高难度的 SpeechIO 测试集中表现一直较差,但在相对纯净的学术集上则表现最优。这正如 [SpeechIO 项目开篇]中提到的,绝对“通用”的语音识别系统并不存在,任何系统都受限于其算法和基础数据的特点,单次单领域的测试都属于偏见,唯有广泛、大规模的评测才能更好更准确的评估语音识别系统。
0条评论|0人参与网友评论

表情
登录|注册
|退出
分享到微博
发布最热评论
最新评论
更多精彩评论>>
头条号入驻

语音之家SpeechHome
助力AI语音开发者的社区
财经自媒体联盟













































 第一财经日报
第一财经日报  每日经济新闻
每日经济新闻  贝壳财经视频
贝壳财经视频  尺度商业
尺度商业  财联社APP
财联社APP  量子位
量子位  财经网
财经网  华商韬略
华商韬略 
4000520066 欢迎批评指正
Copyright © 1996-2019 SINA Corporation
All Rights Reserved 新浪公司 版权所有
All Rights Reserved 新浪公司 版权所有
