
亮点速览
■ 紫光展锐自主研发端侧AI大模型推理框架,深度整合业内开源大模型,全面赋能各项业务;
■ 已成功适配Tinyllama 1.1B,谷歌Gemma 2B,阿里通义千问 0.5B/1.8B,微软Phi3 3.8B,商汤Internlm2 1.8B ,面壁智能Minicpm 2B等业内主流大模型;
■ 支持多种量化格式,为用户带来流畅的端侧大模型应用体验。
引言:云端到终端的跨越
2023年以来,以OpenAI公司的ChatGPT(Generative Pre-trained Transformer)为代表的生成式AI技术在全球点燃研发浪潮,从文本到图像,从音乐到视频,从游戏到教育,无一领域不在大力推动AI技术的应用,呈现出“百花齐放”的生动局面。国内AI领域亦风起云涌,上百个超过10亿参数规模的模型如雨后春笋般涌现,共同绘制了一幅“百模大战”的壮丽图景。
然而,随着AI技术的深入应用,AI模型的规模急剧增长,云端推理的成本问题日益凸显,大规模生成式AI的持续拓展面临严峻挑战:
■ 云端推理成本极高,生成式AI规模化拓展难以持续;
■ AI推理规模远高于训练,不仅训练单个模型会消耗大量资源,而且大型生成式AI模型的推理成本将随着日活用户数量及其使用频率的增加而增加。
AI大模型技术向终端设备迁移成为必然趋势,端侧AI大模型应运而生。端侧AI大模型,是指终端设备上运行大规模人工智能模型,随着智能手机和其他移动设备的计算能力不断增强,它们为这些复杂的AI模型提供了必要的硬件支持。
紫光展锐在端侧大模型领域重点发展的关键技术
展锐在端侧大模型领域进行了深入布局和研究,下面分别针对模型轻量化、芯片支持、软硬件适配三项关键技术进行展开:
模型轻量化
通过量化、剪枝、知识蒸馏等先进技术为AI模型瘦身,有效降低模型复杂度与资源消耗,同时保持高精度,提升部署效率与性能。

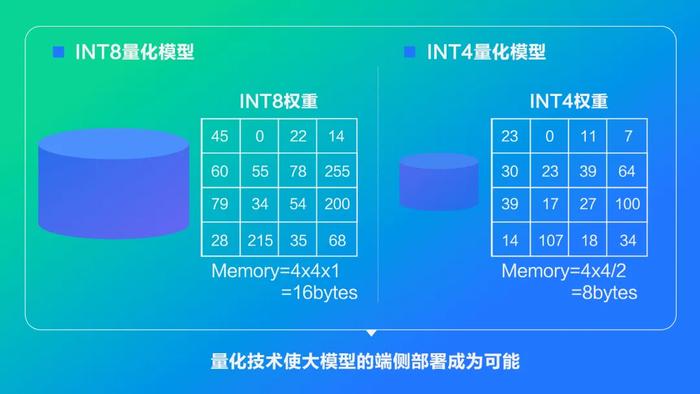
模型量化是指将神经网络的浮点算法转换为定点。浮点模型权重和激活以FP32精度存储和计算,对存储和计算资源的占用较大。以文生图SD模型为例,直接部署浮点模型,运行消耗内存近10GB,这在内存小于12GB的手机上几乎无法推理。
量化技术可以有效降低模型存储和计算资源占用,这对于参数和计算量都很庞大的大模型来说尤为重要。以INT8量化模型为例,相较于浮点模型,可以降低75%的资源占用。模型经过INT8量化后,可以直接在NPU上运行,利用NPU对AI任务的加速能力,加速模型的推理。
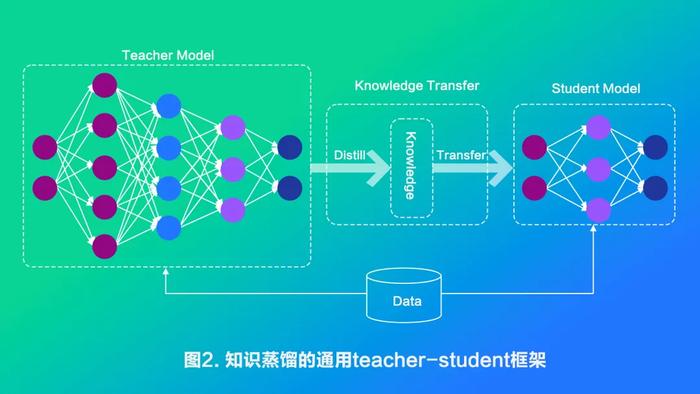
蒸馏是一种基于教师-学生网络思想的训练方法,通过让一个小型的学生模型学习一个大型的教师模型的知识,从而实现模型的压缩。
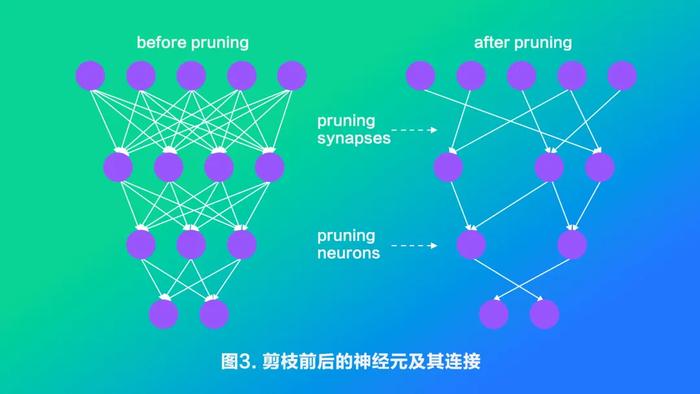
深度学习模型中一般存在着大量冗余的参数,将权重矩阵中相对“不重要”的权值剔除(即置为0),可达到降低计算资源消耗和提高实时性的效果,而对应的技术则被称为模型剪枝。
芯片支持
在端侧运行大模型,需要芯片具备以下几点关键特性:
■ 高性能计算能力:端侧大模型通常包含数十亿的参数,需要强大的运算能力来处理复杂的数学运算。这通常意味着需要GPU(图形处理器)、NPU(神经网络处理器)或专用的AI加速器,它们能够并行处理大量数据,提供高效的矩阵和向量运算;
■ 高内存带宽:大模型在运行时需要大量的内存来存储模型参数和中间结果。因此,芯片需要配备高速缓存和高带宽的内存接口,以确保数据的快速读取和写;
■ 低功耗设计:端侧设备往往对功耗有严格要求,特别是在移动设备和物联网设备上。因此,芯片需要采用低功耗设计,如优化的架构、动态电压和频率调整等技术,以延长设备的电池寿命。
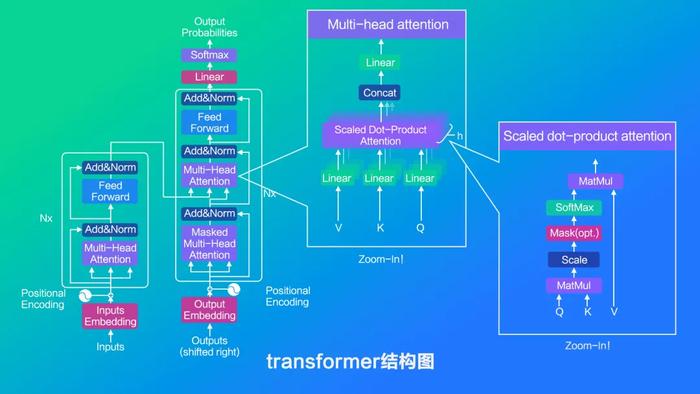
软硬件适配
AI计算部署在终端设备上面临诸多挑战,如芯片种类复杂、异构算力利用率低、算法框架兼容性差、精度损失、AI框架碎片化等问题。
各家芯片厂商都积极自研适用于自家芯片平台的AI异构计算推理框架:前端支持主流神经网络训练框架的AI模型,后端支持多个硬件计算设备,如CPU、NPU和GPU等,同时提供模型轻量化技术等。致力于将AI大模型轻量化,将计算任务分配到不同的硬件计算单元,从而确保端侧AI大模型的稳定运行与高效表现。
在AI领域,异构计算的应用场景包括但不限于高性能计算(HPC)、人工智能训练与推理、物联网与边缘计算、5G通信、多媒体处理和云计算等。例如,在高性能计算场景中,异构计算可以加速汽车建模仿真、电子自动化设计与验证、生命科学等领域的计算任务;在人工智能场景中,它能够支持深度学习训练和推理过程中的大量矩阵运算,尤其是在大规模互联网应用中,如推荐系统、广告和搜索等。
紫光展锐在端侧大模型领域的布局和成果
紫光展锐紧跟当前业界端侧AI技术趋势,在轻量化技术、自研大模型推理框架领域都进行了布局,并构建了全新一代的AI计算平台,提供算法、软件、硬件全栈解决方案,与产业合作伙伴在相关领域建立紧密合作,推动芯片应用生态的建设与行业落地。
轻量化技术的研究
紫光展锐自研的UniQuant是一款AI模型量化和压缩工具,包含了多种先进的训练后量化算法,可以有效地减少模型的大小和计算量,提高模型的运行速度和效率。紫光展锐深入探索并实践多种模型轻量化技术,成功将大型AI模型压缩至适合终端设备运行的规模,使其保持高效能的同时降低能耗。
自研大模型推理框架
自主研发高效、灵活的端侧AI大模型推理框架,支持多种模型格式与量化策略,支持kv cache、混合量化等大模型加速关键技术,基于展锐芯片平台支持高性能异构推理加速,大幅提升端侧大模型推理性能,为端侧高效运行生成式AI提供了可能,实现模型与终端设备的无缝对接,优化系统架构,确保端侧AI大模型在不同设备上的稳定运行与高效表现。
目前,紫光展锐的端侧大模型已成功适配TinyLlama 1.1B,Google Gemma 2B,阿里通义千问0.5B/1.8B,Microsoft Phi3 3.8B,商汤Internlm2 1.8B ,面壁智能Minicpm 2B等业内主流大模型, 在T820和S8000硬件平台实现了Tinyllama 1.1B首次推理延迟小于1s,推理最高可达12tokens/s。
端侧大模型趋势展望
随着技术的不断进步与应用的持续拓展,端侧AI大模型将引领一场深刻的交互体验革命。
未来的AI 智能体不再局限于单一的交互模式,而是融合了屏幕显示、语音对话、甚至是视觉和听觉感知等多种能力,成为了一个能够理解复杂指令、执行多样化任务的“超级助手”。它们可以根据用户的习惯和需求,提供定制化的服务,从日常事务管理到专业信息查询,无所不包。
在智能出行领域,端侧AI将赋能自动驾驶系统,实现更精准、更安全的驾驶体验;在PC与物联网设备中,端侧AI将让每一台设备都具备智能感知与交互能力,构建更加智能、便捷的生活与工作环境。
紫光展锐将持续深耕端侧AI技术,开拓商用AI终端新应用、新场景、新形态,为生产力提供数字化和智能化的先进工具,让端侧AI惠及千行百业。


