
整理 | 屠敏
出品 | CSDN(ID:CSDNnews)
没有任何公告、没有发布博客文章、没有营销宣传,就连 README.md 也是空空如也,DeepSeek 悄悄在深夜上线了一款 685B 的大模型——DeepSeek-V3-0324,并直接发布在 Hugging Face(https://huggingface.co/deepseek-ai)。
即使如此低调,该模型一经上线仍然引发了业界广泛关注。
和之前 DeepSeek v3 版本所采用的自定义许可证有所不同,DeepSeek-V3-0324 采用的是 MIT 开源协议,允许开发人员可以在商业项目中使用,并且几乎不受任何限制地对其进行修改。
DeepSeek-V3-0324 依然采用 Mixture-of-Experts(MoE)架构,与传统大模型相比,计算效率大幅提升。其总参数量高达 6850 亿,但实际在特定任务期间仅激活约 370 亿参数,从而降低计算成本。
此外,该模型引入了两项关键技术:
多头潜在注意力(MLA):增强了模型在长篇文本中保持上下文的能力。
多标记预测(MTP):允许每一步生成多个 token。
这两项技术让 DeepSeek-V3-0324 在推理效率和长文本处理能力上表现更优,将输出速度提高了近 80%。
当然,DeepSeek-V3-0324 这一次吸引众人关注,不仅是因为其强大的能力,还因为其部署方式——它可在高端消费级硬件上本地运行,特别是搭载 M3 Ultra 芯片的 Apple Studio。
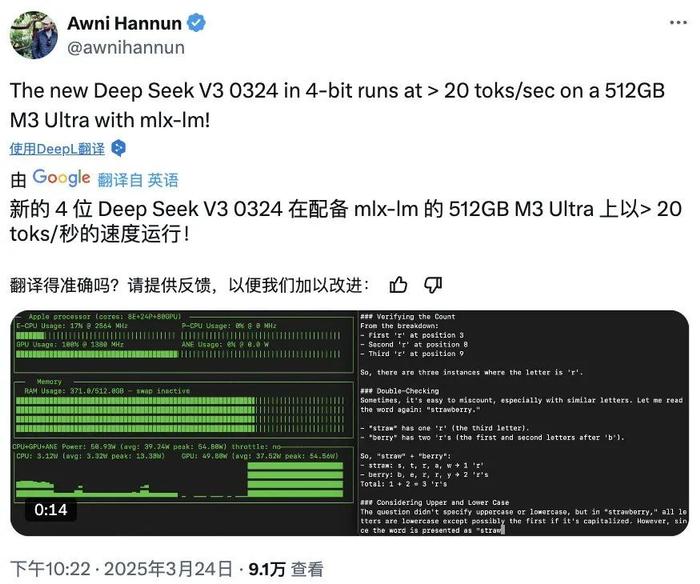
对此,苹果机器学习工程师、AI 研究员 Awni Hannun 在社交媒体 X 上表示:“4 位量化后的 DeepSeek-V3-0324,在搭载 mlx-lm 的 512GB M3 Ultra 上,推理速度可达每秒 20 个 token!”
虽然说售价 74249 元起的 Mac Studio 并非普通大众级设备,但能够在本地运行如此庞大的模型的能力与通常与最先进 AI 相关的数据中心要求大不相同。
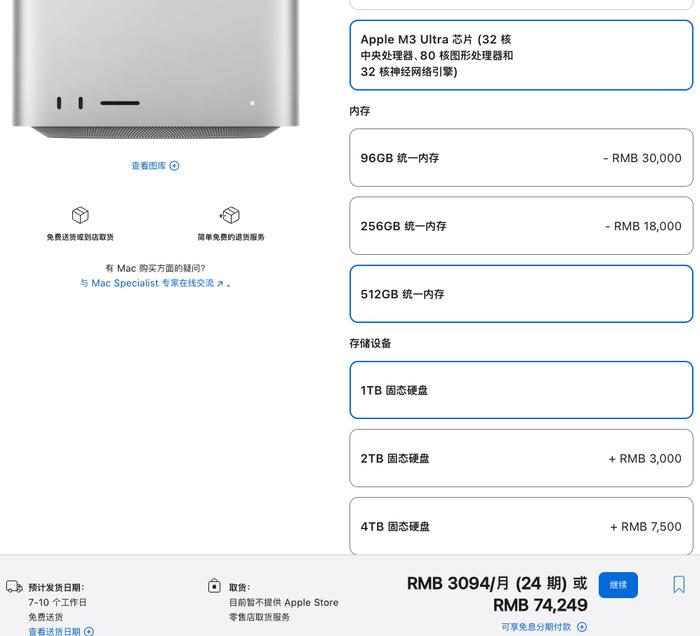
开发者工具专家 Simon Willison 指出,经过 4-bit 量化后,该模型的存储占用减少至 352GB,使其能够在搭载 M3 Ultra 芯片的高端消费级硬件上运行。
Simon Willison 称,如果你有这台机器,就可以用他的开源 llm-mlx 插件(https://github.com/simonw/llm-mlx)运行它,不过其自己还没试过:
llm mlx download-model mlx-community/DeepSeek-V3-0324-4bit
llm chat -m mlx-community/DeepSeek-V3-0324-4bit
这一突破意味着,过去依赖多张 Nvidia GPU、高功耗数据中心运行的大模型,如今可以在功耗不到 200 瓦的 Mac Studio 上运行,挑战了 AI 行业对基础设施需求的传统认知。
除此之外,在这款模型上线之后,很多人也进行了比较。AI 研究员 Xeophon 在 X.com 上表示:“DeepSeek V3 在所有指标上均大幅进步,已是最强的开源非推理模型,超越了 Sonnet 3.5。”

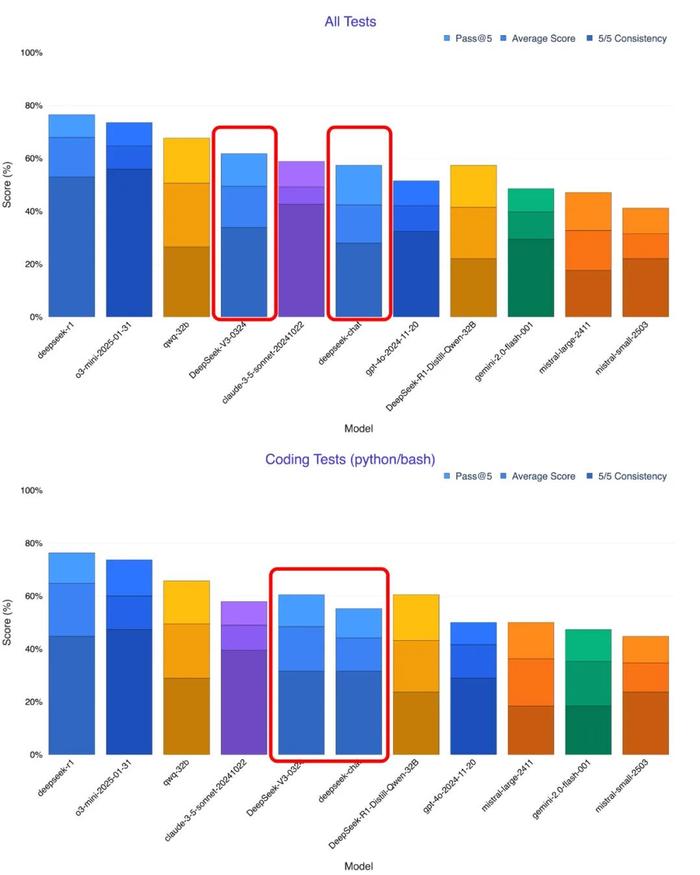
如果更多测试验证这一结论,它的表现甚至可能优于当前商业 AI 领先者 Claude Sonnet 3.5。更重要的是,DeepSeek-V3-0324 完全开源,任何人都可以免费下载使用,而 Sonnet 3.5 仍需要付费订阅。这让 DeepSeek 在开源 AI 生态中更具吸引力。
有业内人士推测,DeepSeek-V3-0324 可能是 DeepSeek-R2 的基础版本。
如果 R2 延续 R1 的发展路径,它或将成为 OpenAI 即将发布的 GPT-5 的有力竞争者。两者的路线截然不同——OpenAI 依赖封闭生态和巨额资金,而 DeepSeek 选择开源和高效计算,AI 未来的竞争格局或将因此改变。
当前,用户可通过多种方式体验这一新模型:
本地运行:模型权重已发布至 Hugging Face(https://huggingface.co/deepseek-ai/DeepSeek-V3-0324),但需强大硬件支持。
云端推理:OpenRouter 提供免费 API 访问,支持对话体验;也有用户猜测 DeepSeek 官方聊天平台(chat.deepseek.com)可能已更新至最新模型,因为感觉体验有所提升。



财经自媒体联盟













































 第一财经日报
第一财经日报  每日经济新闻
每日经济新闻  贝壳财经视频
贝壳财经视频  尺度商业
尺度商业  财联社APP
财联社APP  量子位
量子位  财经网
财经网  华商韬略
华商韬略 
4000520066 欢迎批评指正
All Rights Reserved 新浪公司 版权所有
