



整理 | 郑丽媛
出品 | CSDN(ID:CSDNnews)
如果要衡量 AI 的智能程度,你会怎么做?让它解数学题、写代码,还是让它通过标准化考试?这些方法虽然严谨,但普通人往往难以直观理解 AI 的能力差异。
近来,一位高三学生 Adi Singh 找到了一个更有趣的办法——用《我的世界》(Minecraft)来评测 AI!他创建了一个名为 MC-Bench 的网站,让不同的 AI 大模型在《我的世界》里建造建筑物,然后由网友投票评选出表现最好的模型。
据悉,这个项目迅速吸引了大量 AI 研究人员和开发者的关注,OpenAI、Google、Anthropic 和阿里巴巴等大型企业虽未直接参与开发,但也为该项目提供了 AI 计算资源支持。

一名高中生,创建了一种新的 AI 评测基准
如今,研究人员通常会使用标准化测试来评估 AI 模型的表现,但许多测试都给了AI“主场优势”。
由于 AI 模型的训练方式,它们一般较为擅长解决特定、狭窄的问题,尤其是需要死记硬背或简单推理的任务。例如,AI 模型在 LSAT 法律考试、数学推理测试等标准化考试中得分很高,但在现实应用中仍然容易犯低级错误。
OpenAI 的 GPT-4 能在美国法学院入学考试(LSAT) 中能超越 88% 的人类,却无法数清楚“strawberry”这个单词中有几个“R”。
Anthropic 的 Claude 3.7 编码能力表现出色,在标准化软件工程测试中的准确率达到了 62.3%,但玩《宝可梦》时却不如一个 5 岁小孩。
这种现象,在 AI 圈被部分人称为"基准测试的陷阱"——大模型为特定测试过度优化,就像为考试而生的学霸,解决实际问题时却可能"战五渣"。这说明,仅靠这种标准化测试无法全面衡量 AI 的真实能力。
在此背景下,Adi Singh 独立开发了一个创新性 AI 评测基准 MC-Bench,其核心机制为:
(1)让不同的 AI 模型在《我的世界》里根据相同的提示生成建筑作品,比如“晶莹剔透的酒杯装满了深红色的葡萄酒,反射出美丽的光芒。”;
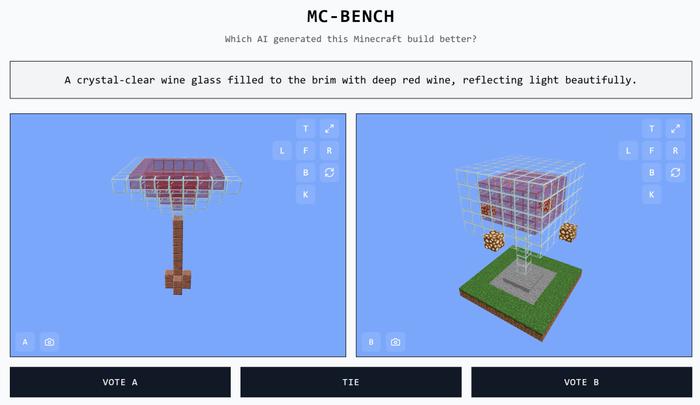
(2)由用户投票选出更好的作品,选择 A 或者 B 或者平局;
(3)投票结束后,系统才会揭晓哪个 AI 完成了哪项建造任务。


为什么选择《我的世界》?AI 评测的新思路
“《我的世界》能让人们更直观看出 AI 发展的进步。大家对这款游戏的画风和氛围都很熟悉。”
诚如 Adi Singh 所说,MC-Bench 比传统的 AI 评测更直观,也更能反映 AI 在实际应用中的表现。最重要的是,游戏环境提供了一个安全可控的测试场所,有助于研究 AI 的推理和规划能力:“游戏或许可以成为一种测试‘自主推理能力’的媒介,比现实世界中的测试更安全,也更容易控制,因此我认为这种方式更理想。”
具体来说,相较于如今难以全面衡量大模型实际能力的传统 AI 评测方式,游戏化评测有着一些独到优势:
(1)模拟真实世界复杂度:游戏往往包含多层次挑战,可考验 AI 的问题解决能力、策略思维和适应能力;(2)评估 AI 的自主决策能力:在游戏环境中,AI 需要独立做出决策,而不仅仅是执行预定义的任务;(3)可控环境:游戏提供了可重复测试的环境,可以在相同条件下对比不同 AI 的表现;(4)安全性:与直接在现实世界中部署 AI 相比,游戏环境为 AI 评测提供了更安全的测试空间。
基于此,Adi Singh 坚信:游戏化评测有望成为未来 AI 评测的重要趋势,因为它不仅让 AI 研究变得更有趣,也让普通人能够更直观地理解 AI 发展水平。
而他之所以选择《我的世界》作为评测对象,很大程度上是因为它的广泛知名度——毕竟,这是全球销量最高的电子游戏之一,即使是不玩游戏的人,也可以直观地判断哪个方块版的“酒杯”更符合实际。
全球用户群体:《我的世界》全球有上亿玩家,可轻松吸引大量用户参与 AI 评测,形成众包数据。
易于理解和评判:相比代码输出或文本生成,视觉化的建筑作品更容易让普通用户参与评测。你不需要懂编程,也能看出哪座建筑更有创意和写实。
测试 AI 的复杂能力:建造建筑不仅考验 AI 的生成能力,还涉及逻辑推理、规划、空间认知等能力,而这正是传统 AI 评测难以全面覆盖的。
事实上,MC-Bench 从技术上来说也是一个编程基准测试,因为 AI 模型需要编写代码来完成建造任务,例如:“堆雪人”或“在宁静的沙滩上建造一座迷人的热带小屋”——只不过,MC-Bench 通过视觉化的方式降低了参与门槛,使得任何人都能轻易参与到 AI 模型的评测中来。这种方式不仅增加了项目的吸引力,也为收集关于 AI 性能的数据提供了新的途径。

大型 AI 公司支持,8 名志愿者推动
目前,MC-Bench 是一个公开网站(https://mcbench.ai/),任何人都可以访问、评判 AI 生成的作品,并给出自己的投票数据。根据 MC-Bench 官网来看,其团队仅由 8 名志愿者组成,以维持日常的开发和维护工作:
此外,Anthropic、Google、OpenAI 和阿里巴巴等大型 AI 公司提供了模型访问权限,用于基准测试,不过与该项目并无官方合作关系:

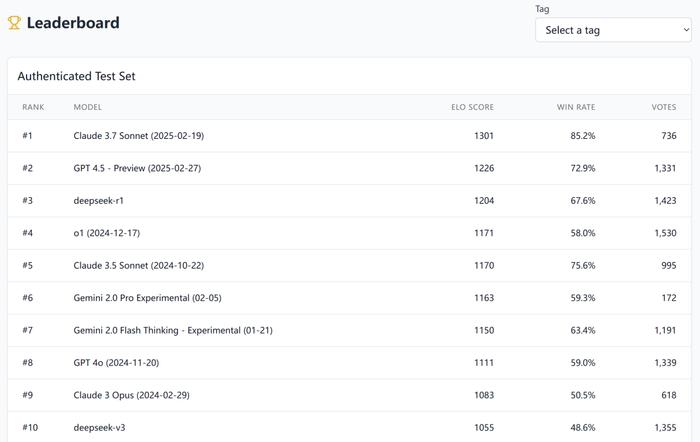
从 MC-Bench 官方给出的胜率最高的 Top 10 大模型名单来看,Claude 3.7 Sonnet 目前位居第一,而近来爆火的 DeepSeek-R1 排在第三名。
当前,MC-Bench 主要测试的还是基础建造能力,以评估 AI 从 GPT-3 时代发展至今的进步。至于未来规划,Adi Singh 透露:他计划拓展到更复杂的任务,比如长期规划和目标导向型任务。
不仅如此,他还补充道,MC-Bench 的排行榜与他的个人体验高度一致,说明该平台确实能为用户提供有价值的见解:
“目前的排行榜基本符合我自己在使用这些模型时的体验,这点与很多纯文本基准测试不同。或许 MC-Bench 可以帮助 AI 公司判断自己是否在朝着正确的方向前进。”
也许,未来的 AI 评测方式,不再是刷题,而是“玩游戏玩”出来的——你觉得这种方式靠谱吗?
参考链接:
https://bitcoinworld.co.in/minecraft-ai-benchmark-highschooler-website/
https://autogpt.net/high-schooler-builds-website-for-ai-minecraft-battles/


财经自媒体联盟













































 第一财经日报
第一财经日报  每日经济新闻
每日经济新闻  贝壳财经视频
贝壳财经视频  尺度商业
尺度商业  财联社APP
财联社APP  量子位
量子位  财经网
财经网  华商韬略
华商韬略 
4000520066 欢迎批评指正
All Rights Reserved 新浪公司 版权所有
