
DeepSeek

DeepSeek于2025年2月24日正式启动“开源周”,计划连续5天每天开源一个项目。
编辑 | 数据君
2月21日,DeepSeek发文称,构建了一支探索AGI(通用人工智能)小团队,从下周起将开源5个代码库,以完全透明的方式分享研究进展。

DeepSeek于2025年2月24日正式启动“开源周”,计划连续5天每天开源一个项目。
开源周首日:FlashMLA 开启高效 AI 加速新时代
DeepSeek开源周的第一个项目为FlashMLA,可以理解为专门为高性能显卡(Hopper GPU)设计的“AI加速工具”。
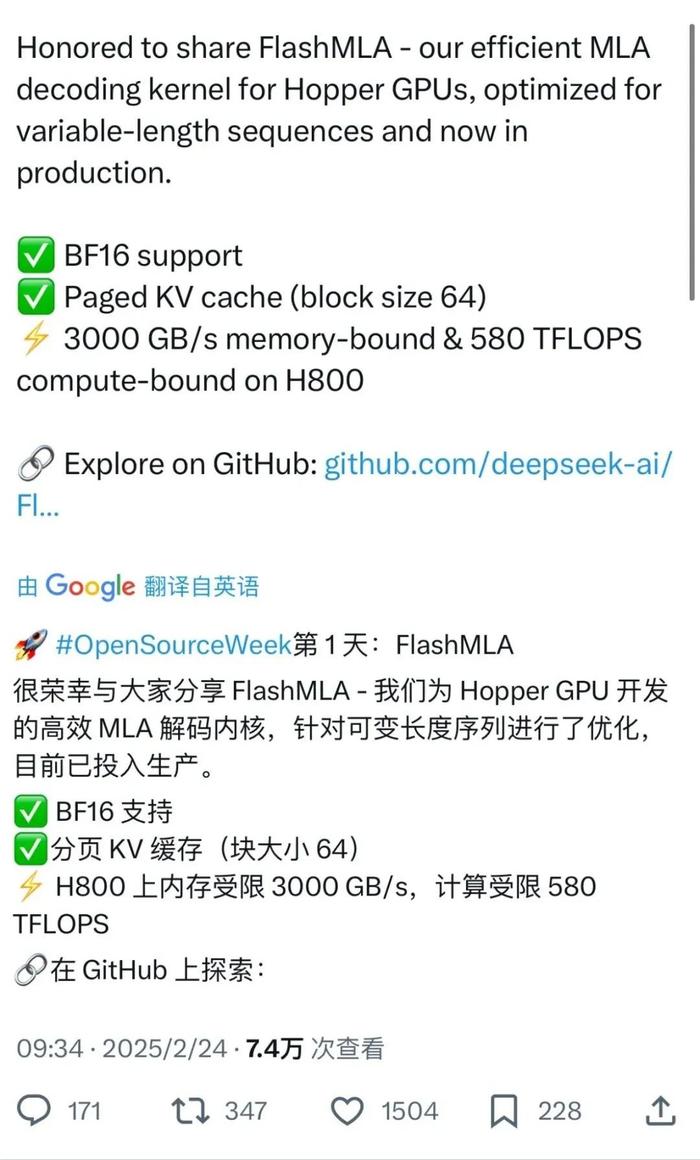
主要针对可变长度序列的推理服务进行优化,目前已投入生产使用。在 H800 GPU 运行环境下,它实现了 3000GB/s 的内存带宽以及 580TFLOPS 的计算性能,展现出当前 AI 计算领域的顶尖实力。例如,当 AI 同时处理长句子和短句子等不同长度的文本序列时,FlashMLA 能够智能地动态调整资源分配,避免算力浪费。其支持 BF16 格式,优化存储带宽使用率,采用分页 KV 缓存机制减少显存占用,通过优化访存和计算路径最大化利用 GPU 资源,有效减少推理延迟,为大语言模型运行中的算力瓶颈和成本问题提供了创新性解决方案。
FlashMLA 的开源收获了众多开发者的赞誉,网友们纷纷点赞,向 DeepSeek 工程团队致敬。有人感慨 “DeepSeek 王炸开局”,也有人称赞 “‘源’神启动!”,甚至有人评价 “DeepSeek 是真正的 Open AI” 。
开源次日:DeepEP 为 MoE 模型带来通信革新
2月25日,DeepSeek再度官宣,今日开源代码库为DeepEP,它是首个用于 MoE 模型训练和推理的开源EP通信库。

DeepEP 具备诸多显著优势:在通信效率上,实现了高效的全员沟通;在硬件支持方面,节点内和节点间均支持 NVLink 和 RDMA;在计算内核上,拥有用于训练和推理预填充的高吞吐量内核以及用于推理解码的低延迟内核;同时,它还提供原生 FP8 调度支持,以及灵活的 GPU 资源控制,实现计算 - 通信重叠,从而全方位提升 MoE 模型训练和推理的性能,为 MoE 模型的发展注入新的活力。与其他同类通信库相比,DeepEP 在性能和功能上展现出独特的竞争力,有望成为 MoE 模型开发者的首选工具。
值得一提的是,DeepSeek 此次选择先在 GitHub 上线 DeepEP,然后再通过官方账号发布上新通知,这种发布方式迅速吸引了 GitHub 上大量开发者的关注,短时间内就收获了众多的关注和讨论,进一步扩大了 DeepEP 的影响力。
开源周启动仅两天,GitHub仓库星标数已破万,全球开发者社区涌现大量二次开发案例。
DeepSeek:厚积薄发的 AI 研发力量
DeepSeek,全称杭州深度求索人工智能基础技术研究有限公司,于 2023 年 7 月 17 日由知名私募巨头幻方量化孕育而生。其团队汇聚人工智能、计算机科学、数学等多领域专业人才,凭借对 AI 技术的热爱与执着,在大语言模型及相关技术研发道路上不断探索。自成立以来,DeepSeek 成果丰硕,2024 年密集发布多个模型。

2024年1月,推出首个大语言模型DeepSeekLLM,探索模型通用能力;
2月,发布专攻数学推理的DeepSeekMath,在复杂问题求解上比肩人类专家;
5月,基于MoE架构的DeepSeek-V2登陆LMSYS竞技场,跻身全球聊天机器人第一梯队;
12月,开源DeepSeek-V3,成为全球开发者社区的热门选择;
2025年初,DeepSeek-R1模型通过NVIDIA NIM平台接入亚马逊、微软云服务,英伟达称其为“最先进的大语言模型”。
值得注意的是,DeepSeek的开源并非“技术倾销”,而是经过严密设计的技术输出:从FlashMLA的硬件适配到DeepEP的集群通信优化,均瞄准实际生产中的关键痛点,既降低使用门槛,又为深度合作留出接口。
无论何种选择,DeepSeek的开源周已传递明确信号:AGI的未来属于开放协作。当技术壁垒被打破,创新速度将以指数级增长——而这或许正是人类触及通用人工智能的必经之路。


财经自媒体联盟













































 第一财经日报
第一财经日报  每日经济新闻
每日经济新闻  贝壳财经视频
贝壳财经视频  尺度商业
尺度商业  财联社APP
财联社APP  量子位
量子位  财经网
财经网  华商韬略
华商韬略 
4000520066 欢迎批评指正
All Rights Reserved 新浪公司 版权所有
